你好,欢迎来到我的博客
· 阅读需 1 分钟

最近龙虾OpenClaw真是火爆了,有很多小伙伴都来问阿赞,该怎么安装一个自己的龙虾?

我们看一下最终的样子,安装指南来了!
读完本篇文章,你可以学会:在自己的电脑上安装一个自己的龙虾,并用飞书来直接跟他聊天,完全不需要任何编程基础,纯小白也能轻松上手!
首先,你需要一台可以连接互联网的电脑
Windows、MacOS、Linux 都可以
有不少已经上网搜索过龙虾的小伙伴会问:Windows、MacOS、Linux 哪个系统更适合安装龙虾? 我是否应该买一台Mac Mini?
在阿赞的角度来看:MacOS 肯定是独一档的好
因为有着更好的稳定性,更强的性能,更低的功耗,让Mac Mini成为最适合龙虾的机器
但是其他系统也完全可以使用,如果不是重度依赖龙虾工作,你完全没有必要额外去买一台Mac Mini,在现有的电脑上安装使用足矣。
其次,你需要一个大模型的API接口
你可以买任何你觉得好用的大模型API接口,OpenAI、Anthropic、国内的模型厂商都可以
如果你没有预算,完全可以使用免费的模型接口,或者你有比较不错的显卡,那么你完全可以选择在本地部署一个开源模型,来当做龙虾的后端引擎。
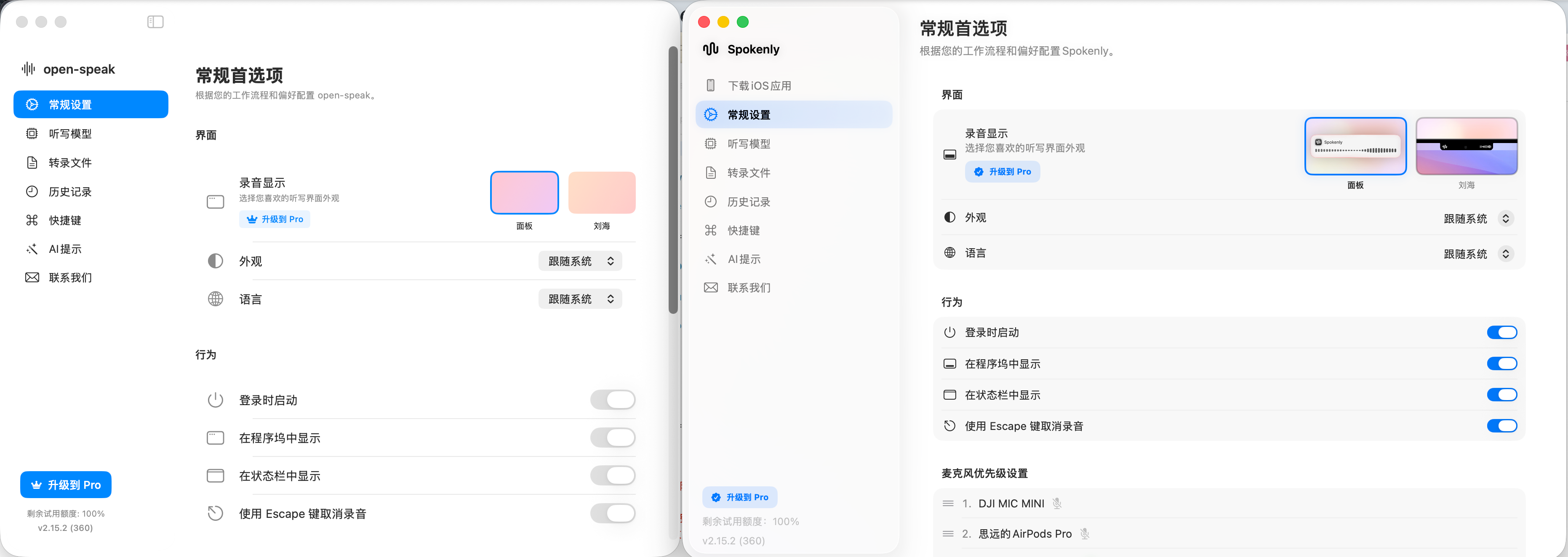
我相信绝大多数小伙伴都有windows电脑,所以我们以Windows系统为例,来介绍一下安装的步骤。
MacOS 和 Linux 的安装步骤基本上是一样的,唯一的区别就是第一步安装 Docker 的方式不太一样,后续的步骤完全一样。
你可以在下面这个地址找到docker的安装教程,这里我不再赘述
https://www.runoob.com/docker/windows-docker-install.html
安装并启动完成之后,可以看到docker的界面了
打开一个命令行窗口,输入 docker version 来验证一下是否安装成功
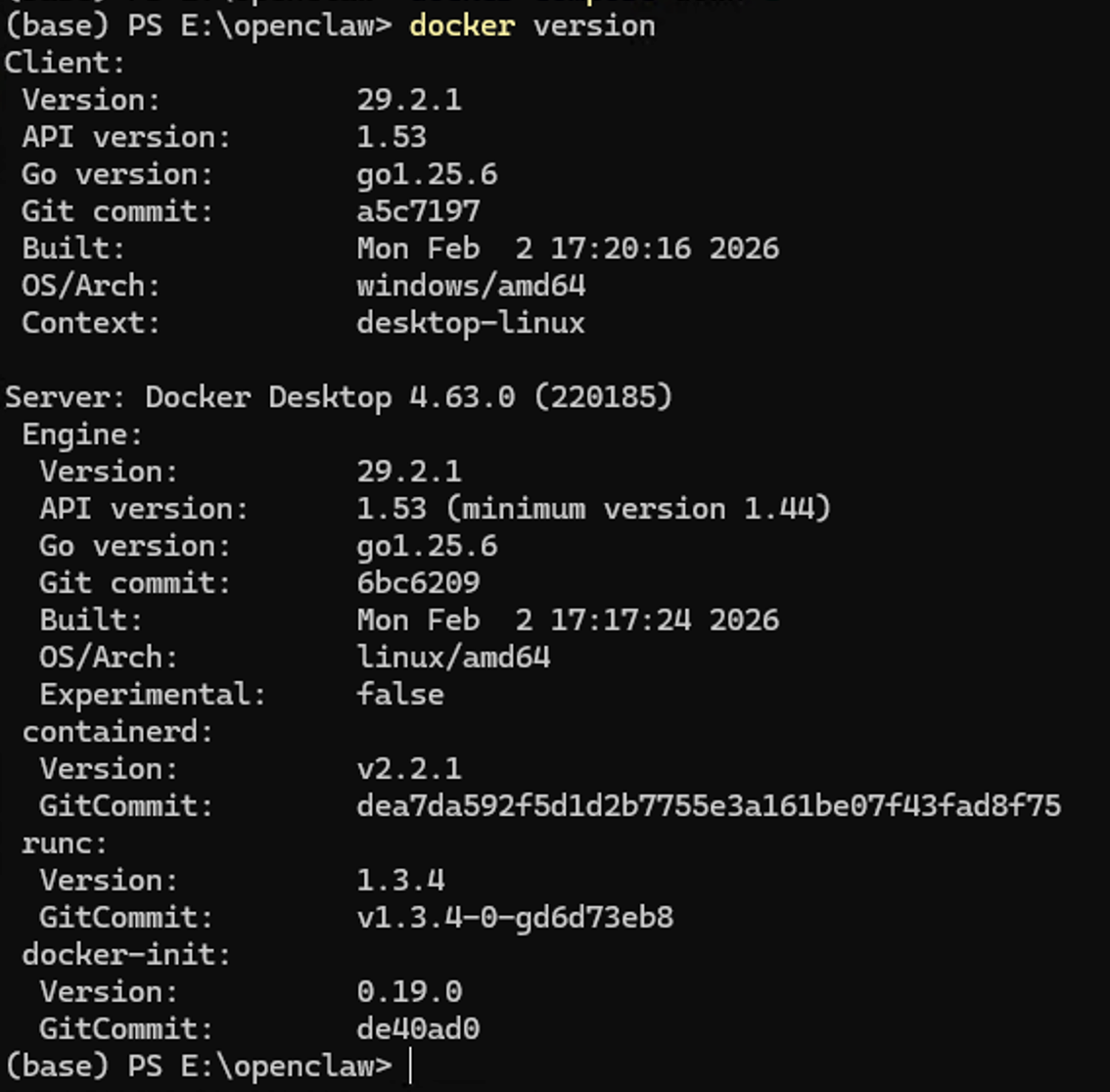
看到如上界面后,就表示docker安装成功了,我们就可以进入下一步了。
这里我们使用了一个已经集成好了国内各种聊天软件的龙虾
Github仓库地址如下,感兴趣的小伙伴可以阅读一下,不感兴趣的直接按照我们下面的步骤来操作 https://github.com/justlovemaki/OpenClaw-Docker-CN-IM
打开一个命令行窗口,输入下面的命令来下载这个龙虾的docker镜像
docker pull justlovemaki/openclaw-docker-cn-im:latest
如果你没有科学上网的条件,那么大概率上面这个镜像下不下来,没关系我这里也准备了一个国内网络友好的镜像地址
docker pull registry.cn-hangzhou.aliyuncs.com/dongfangzan/openclaw-docker-cn-im:20260309
你也可以在后台私信我回复:龙虾,我已经把这个镜像准备好了

文件下载下来之后,在下载目录,执行下面的命令即可完成导入
docker load -i openclaw.tar
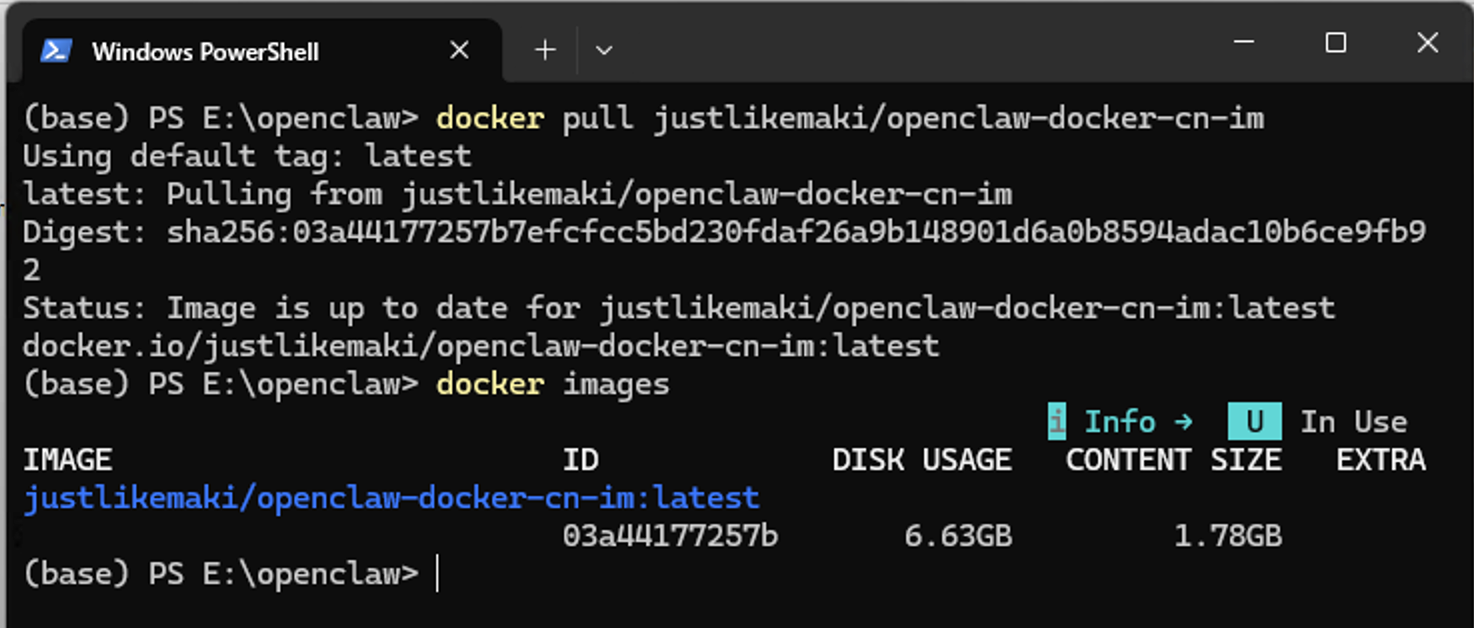
下载完成后,你可以输入下面的命令看到这个镜像
docker images
在你觉得合适的地方,创建一个目录来存放龙虾的数据,比如 E:\openclaw-data
这里可以看到,当前目录是空的,我们现在需要创建一个文本文档,命名为 .env
所有的配置文件,你可以关注我的公众号,并在后台回复:龙虾,我已经把所有涉及到的文件都准备好了
把下面的内容,保存进.env文件中,然后我们开始替换掉里面的内容
# OpenClaw Docker 环境变量配置示例
# 复制此文件为 .env 并修改相应的值
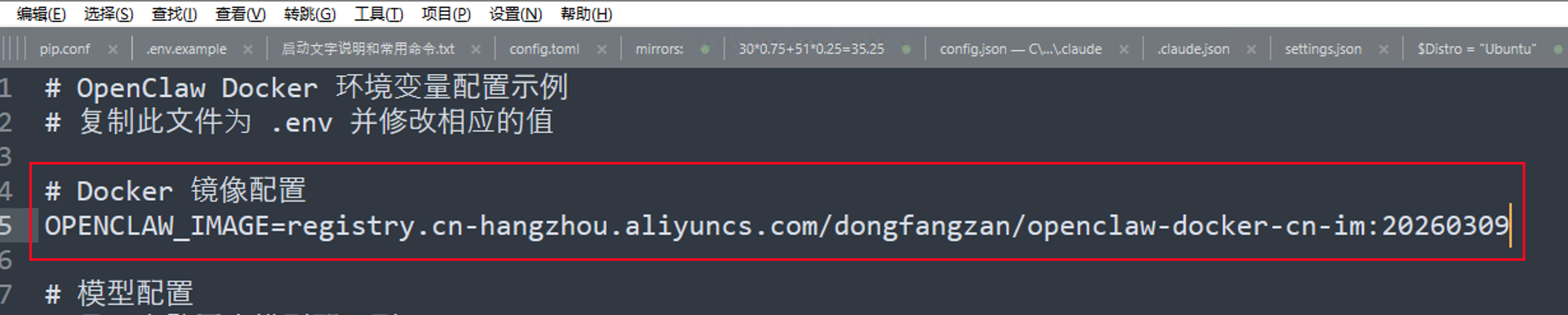
# Docker 镜像配置
OPENCLAW_IMAGE=justlikemaki/openclaw-docker-cn-im:latest
# 模型配置
# 是否自动同步模型配置到 openclaw.json (true/false)
# 如果你手动修改了 openclaw.json 中的模型设置,请将其设为 false
SYNC_MODEL_CONFIG=true
# 提供商 1 (默认)
# 主模型 ID (支持多个,用逗号隔开,第一个将作为默认模型)
MODEL_ID=model id
# 图片模型 ID (可选,留空则使用 MODEL_ID,支持 provider/model 格式)
IMAGE_MODEL_ID=
BASE_URL=http://xxxxx/v1
API_KEY=123456
# API 协议类型: openai-completions 或 anthropic-messages
API_PROTOCOL=openai-completions
# 模型上下文窗口大小
CONTEXT_WINDOW=200000
# 模型最大输出 tokens
MAX_TOKENS=8192
# 提供商 2 (可选)
# MODEL2_NAME=model2
# MODEL2_MODEL_ID=model id1,model id2
# MODEL2_BASE_URL=http://xxxxx/v1
# MODEL2_API_KEY=123456
# MODEL2_PROTOCOL=openai-completions
# MODEL2_CONTEXT_WINDOW=200000
# MODEL2_MAX_TOKENS=8192
# Telegram 配置(可选,留空则不启用)
TELEGRAM_BOT_TOKEN=
# 飞书配置(可选,留空则不启用)
FEISHU_APP_ID=
FEISHU_APP_SECRET=
# 是否启用飞书官方插件 (true/false)
FEISHU_OFFICIAL_PLUGIN_ENABLED=false
# 钉钉配置(可选,留空则不启用)
DINGTALK_CLIENT_ID=
DINGTALK_CLIENT_SECRET=
DINGTALK_ROBOT_CODE=
DINGTALK_CORP_ID=
DINGTALK_AGENT_ID=
# QQ 机器人配置(可选,留空则不启用)
QQBOT_APP_ID=
QQBOT_CLIENT_SECRET=
# NapCat (OneBot v11) 配置(可选,留空则不启用)
# NapCat 反向 WS 监听端口(NapCat 主动连接到此端口)
NAPCAT_REVERSE_WS_PORT=
# NapCat HTTP API 地址(可选,用于主动发送消息)
NAPCAT_HTTP_URL=
# 连接鉴权 Token(与 NapCat 侧保持一致)
NAPCAT_ACCESS_TOKEN=
# 管理员用户 ID,多个用逗号分隔
NAPCAT_ADMINS=
# 企业微信配置(可选,留空则不启用)
# 方式1:单账号(兼容旧格式),会自动同步为 channels.wecom.default
WECOM_TOKEN=
WECOM_ENCODING_AES_KEY=
# 方式2:多账号(Multi-Bot)JSON,支持 bot1/bot2... 独立配置(会与现有配置深度合并)
# 注意:.env 中 JSON 需要写成单行
# 示例:{"bot1":{"token":"t1","encodingAesKey":"k1","agent":{"corpId":"wwxxx","corpSecret":"s1","agentId":1000001}},"bot2":{"token":"t2","encodingAesKey":"k2","agent":{"corpId":"wwxxx","corpSecret":"s2","agentId":1000002}}}
WECOM_BOTS_JSON=
# 工作空间配置(不要更改)
WORKSPACE=/home/node/.openclaw/workspace
# 挂载目录配置(按实际更改)
# OpenClaw 数据目录(包含配置文件、工作空间等所有数据)
OPENCLAW_DATA_DIR=~/.openclaw
# 可选:容器启动用户 UID:GID
# 默认 0:0(root)用于 init.sh 自动修复挂载目录权限,再降权为 node 启动服务
# 如需与宿主机用户对齐,可设置为 1000:1000 或 Linux 上的 $(id -u):$(id -g)
OPENCLAW_RUN_USER=0:0
# Gateway 配置
## 网关 token,用于认证(按实际更改)
OPENCLAW_GATEWAY_TOKEN=123456
OPENCLAW_GATEWAY_BIND=lan
OPENCLAW_GATEWAY_PORT=18789
OPENCLAW_BRIDGE_PORT=18790
OPENCLAW_GATEWAY_MODE=local
# 允许的 Origin 域,多个用逗号隔开
OPENCLAW_GATEWAY_ALLOWED_ORIGINS=http://localhost
# 允许不安全认证(如 http),可选 true/false
OPENCLAW_GATEWAY_ALLOW_INSECURE_AUTH=true
# 危险:禁用设备认证(如在 Docker 环境中无法获取设备信息),可选 true/false
OPENCLAW_GATEWAY_DANGEROUSLY_DISABLE_DEVICE_AUTH=false
# 插件全局控制
OPENCLAW_PLUGINS_ENABLED=true
# 飞书官方插件独立开关(对应 plugins.entries.feishu-openclaw-plugin.enabled)
# 与旧版 feishu 渠道互斥:
# true = 启用 feishu-openclaw-plugin,并自动禁用旧版 feishu
# false = 禁用 feishu-openclaw-plugin,并自动启用旧版 feishu
# 留空表示不覆盖现有配置;若检测到官方插件已有状态,也会自动与旧版 feishu 做互斥处理
FEISHU_OFFICIAL_PLUGIN_ENABLED=
首先需要注意的是,如果在第二步 中下载的镜像是registry.cn-hangzhou.aliyuncs.com/dongfangzan/openclaw-docker-cn-im:20260309
那么你需要把上面.env文件中的 OPENCLAW_IMAGE 的值,替换成 registry.cn-hangzhou.aliyuncs.com/dongfangzan/openclaw-docker-cn-im:20260309
接下来我们需要替换掉模型相关的配置
注意下面这一块内容,你需要把MODEL_ID、BASE_URL、API_KEY 和 API_PROTOCOL 替换成你自己的大模型接口的相关信息
# 提供商 1 (默认)
# 主模型 ID (支持多个,用逗号隔开,第一个将作为默认模型)
MODEL_ID=model id
# 图片模型 ID (�可选,留空则使用 MODEL_ID,支持 provider/model 格式)
IMAGE_MODEL_ID=
BASE_URL=http://xxxxx/v1
API_KEY=123456
# API 协议类型: openai-completions 或 anthropic-messages
API_PROTOCOL=openai-completions
# 模型上下文窗口大小
CONTEXT_WINDOW=200000
# 模型最大输出 tokens
MAX_TOKENS=8192
在这个步骤中,我们就需要用到大模型的接口了,如果你还没有的话,可以去购买一个,或者使用本地部署的。
我们需要找到你的API Key 和 API Base URL
这个在为你提供大模型接口的厂商那里都可以找��到,通常在控制台的API管理或者密钥管理那里
比如你在阿里云购买了一个Coding Plan的大模型接口,那么就可以按如下进行填写
# 提供商 1 (默认)
# 主模型 ID (支持多个,用逗号隔开,第一个将作为默认模型)
MODEL_ID=qwen3.5-plus
# 图片模型 ID (可选,留空则使用 MODEL_ID,支持 provider/model 格式)
IMAGE_MODEL_ID=
BASE_URL=https://coding.dashscope.aliyuncs.com/v1
API_KEY=sk-xxxxxx
# API 协议类型: openai-completions 或 anthropic-messages
API_PROTOCOL=openai-completions
# 模型上下文窗口大小
CONTEXT_WINDOW=200000
# 模型最大输出 tokens
MAX_TOKENS=8192
然后注意在第78行,现在是OPENCLAW_DATA_DIR=~/.openclaw
需要替换为你在第三步一开始创建的目录 OPENCLAW_DATA_DIR=E:\\openclaw-data\\.openclaw
windows 路径需要使用双斜杠
\\来转义,如果是MacOS 或 Linux 则直接使用单斜杠/即可
替换完成后,保存这个.env文件
可以看到当前目录下目前只有这个.env文件
接着,再打开一个新的文本文件,命名为 docker-compose.yml
把下面的所有内容,复制粘贴到 docker-compose.yml 文件中进行保存
version: '3.8'
x-openclaw-common-env: &openclaw-common-env
TZ: Asia/Shanghai
HOME: /home/node
TERM: xterm-256color
# 模型配置
SYNC_MODEL_CONFIG: ${SYNC_MODEL_CONFIG}
MODEL_ID: ${MODEL_ID}
IMAGE_MODEL_ID: ${IMAGE_MODEL_ID}
BASE_URL: ${BASE_URL}
API_KEY: ${API_KEY}
API_PROTOCOL: ${API_PROTOCOL}
CONTEXT_WINDOW: ${CONTEXT_WINDOW}
MAX_TOKENS: ${MAX_TOKENS}
# 提供商 2 (可选)
MODEL2_NAME: ${MODEL2_NAME}
MODEL2_MODEL_ID: ${MODEL2_MODEL_ID}
MODEL2_BASE_URL: ${MODEL2_BASE_URL}
MODEL2_API_KEY: ${MODEL2_API_KEY}
MODEL2_PROTOCOL: ${MODEL2_PROTOCOL}
MODEL2_CONTEXT_WINDOW: ${MODEL2_CONTEXT_WINDOW}
MODEL2_MAX_TOKENS: ${MODEL2_MAX_TOKENS}
# 通道配置
TELEGRAM_BOT_TOKEN: ${TELEGRAM_BOT_TOKEN}
FEISHU_APP_ID: ${FEISHU_APP_ID}
FEISHU_APP_SECRET: ${FEISHU_APP_SECRET}
DINGTALK_CLIENT_ID: ${DINGTALK_CLIENT_ID}
DINGTALK_CLIENT_SECRET: ${DINGTALK_CLIENT_SECRET}
DINGTALK_ROBOT_CODE: ${DINGTALK_ROBOT_CODE}
DINGTALK_CORP_ID: ${DINGTALK_CORP_ID}
DINGTALK_AGENT_ID: ${DINGTALK_AGENT_ID}
QQBOT_APP_ID: ${QQBOT_APP_ID}
QQBOT_CLIENT_SECRET: ${QQBOT_CLIENT_SECRET}
NAPCAT_REVERSE_WS_PORT: ${NAPCAT_REVERSE_WS_PORT}
NAPCAT_HTTP_URL: ${NAPCAT_HTTP_URL}
NAPCAT_ACCESS_TOKEN: ${NAPCAT_ACCESS_TOKEN}
NAPCAT_ADMINS: ${NAPCAT_ADMINS}
# 企业微信配置
WECOM_TOKEN: ${WECOM_TOKEN}
WECOM_ENCODING_AES_KEY: ${WECOM_ENCODING_AES_KEY}
# 企业微信多账号配置(JSON 字符串,示例见 .env.example)
WECOM_BOTS_JSON: ${WECOM_BOTS_JSON}
# 工作空间配置
WORKSPACE: ${WORKSPACE}
# Gateway 配置
OPENCLAW_GATEWAY_TOKEN: ${OPENCLAW_GATEWAY_TOKEN}
OPENCLAW_GATEWAY_BIND: ${OPENCLAW_GATEWAY_BIND}
OPENCLAW_GATEWAY_PORT: ${OPENCLAW_GATEWAY_PORT}
OPENCLAW_BRIDGE_PORT: ${OPENCLAW_BRIDGE_PORT}
OPENCLAW_GATEWAY_MODE: ${OPENCLAW_GATEWAY_MODE}
OPENCLAW_GATEWAY_ALLOWED_ORIGINS: ${OPENCLAW_GATEWAY_ALLOWED_ORIGINS}
OPENCLAW_GATEWAY_ALLOW_INSECURE_AUTH: ${OPENCLAW_GATEWAY_ALLOW_INSECURE_AUTH}
OPENCLAW_GATEWAY_DANGEROUSLY_DISABLE_DEVICE_AUTH: ${OPENCLAW_GATEWAY_DANGEROUSLY_DISABLE_DEVICE_AUTH}
OPENCLAW_GATEWAY_AUTH_MODE: ${OPENCLAW_GATEWAY_AUTH_MODE}
# 插件控制
OPENCLAW_PLUGINS_ENABLED: ${OPENCLAW_PLUGINS_ENABLED}
FEISHU_OFFICIAL_PLUGIN_ENABLED: ${FEISHU_OFFICIAL_PLUGIN_ENABLED}
services:
openclaw-gateway:
container_name: openclaw-gateway
image: ${OPENCLAW_IMAGE}
cap_add:
- CHOWN
- SETUID
- SETGID
- DAC_OVERRIDE
# 可选:指定容器运行 UID:GID(例如 1000:1000)
# 默认保持 root 启动,以便 init.sh 自动修复挂载卷权限后再降权运行网关
user: ${OPENCLAW_RUN_USER:-0:0}
environment: *openclaw-common-env
volumes:
- ${OPENCLAW_DATA_DIR}:/home/node/.openclaw
# 使用命名卷共享 extensions,确保工具容器安装后的插件主容器可见
- openclaw-extensions:/home/node/.openclaw/extensions
ports:
- "${OPENCLAW_GATEWAY_PORT}:18789"
- "${OPENCLAW_BRIDGE_PORT}:18790"
init: true
restart: unless-stopped
openclaw-installer:
container_name: openclaw-installer
image: ${OPENCLAW_IMAGE}
profiles:
- tools
user: ${OPENCLAW_RUN_USER:-0:0}
environment: *openclaw-common-env
volumes:
- ${OPENCLAW_DATA_DIR}:/home/node/.openclaw
- openclaw-extensions:/home/node/.openclaw/extensions
entrypoint: ["tail", "-f", "/dev/null"]
init: true
restart: 'no'
ports: []
stdin_open: true
tty: true
cap_add:
- CHOWN
- SETUID
- SETGID
- DAC_OVERRIDE
volumes:
openclaw-extensions:
这时,该目录下,就有两个文件了
接下来,我们需要在这个目录下打开一个命令行工具
执行下面的命令
docker-compose up -d
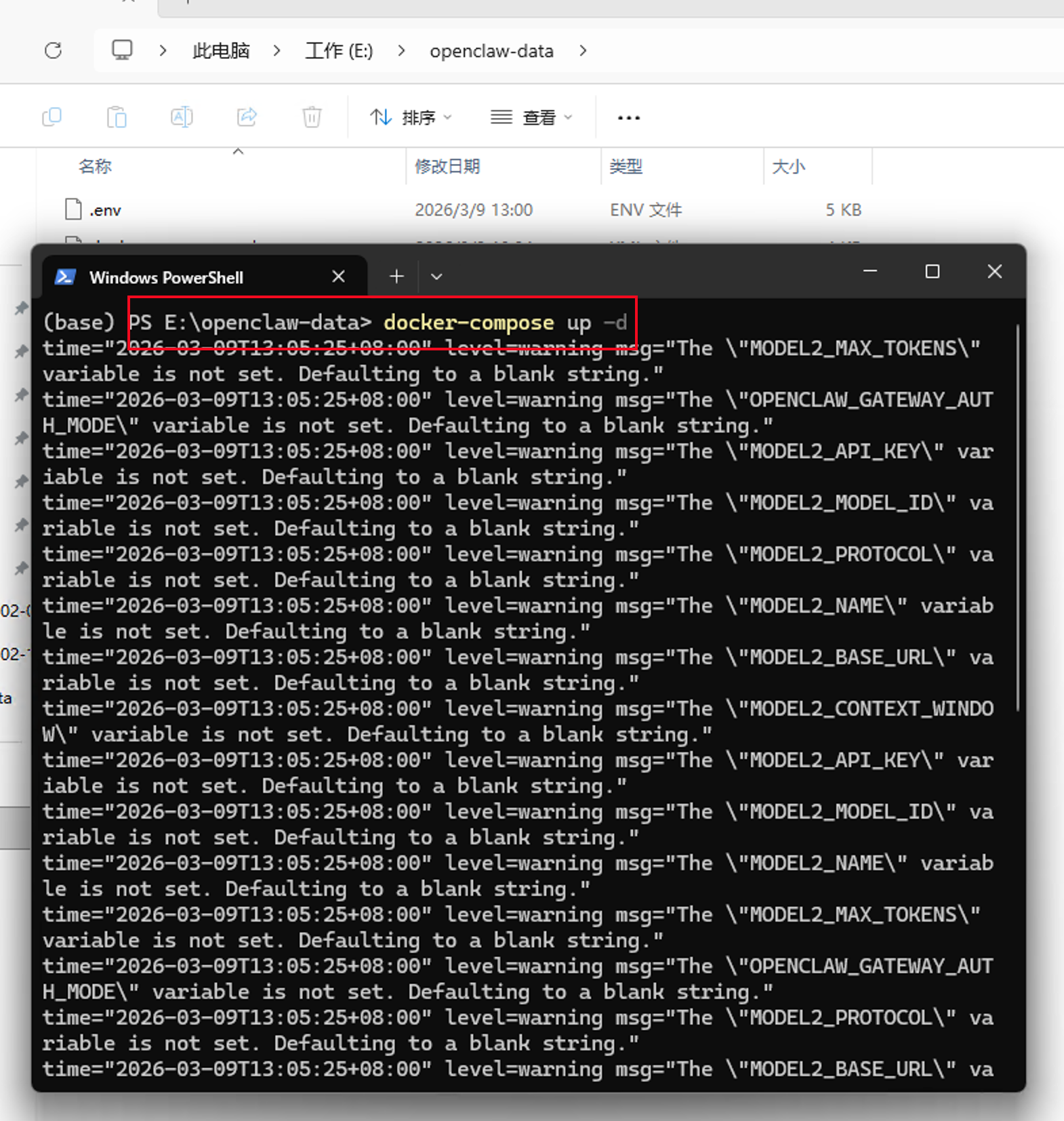
看到最下方有一个绿色的Created,就表示龙虾已经成功启动了
然后我们输入下面的命令
docker logs openclaw-gateway
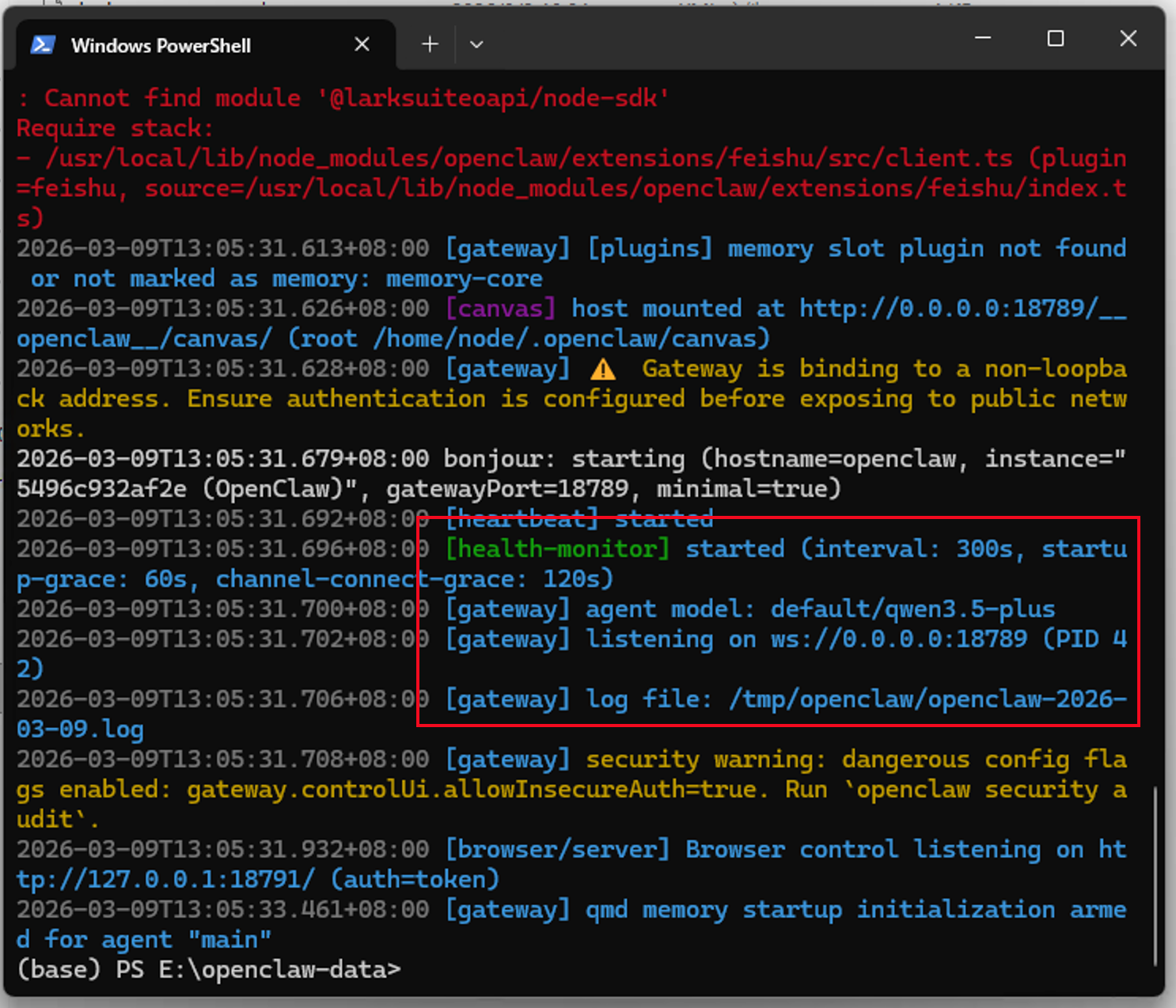
当看到有listening on ws://0.0.0.0:18789的日志输出时,就表示龙虾已经成功启动了
接下来我们输入下面的命令,来进入到龙虾的安装容器中
docker exec -it openclaw-gateway bash
随后输入下面的命令,就进入了与我们的龙虾进行交互时对话的窗口了
openclaw tui
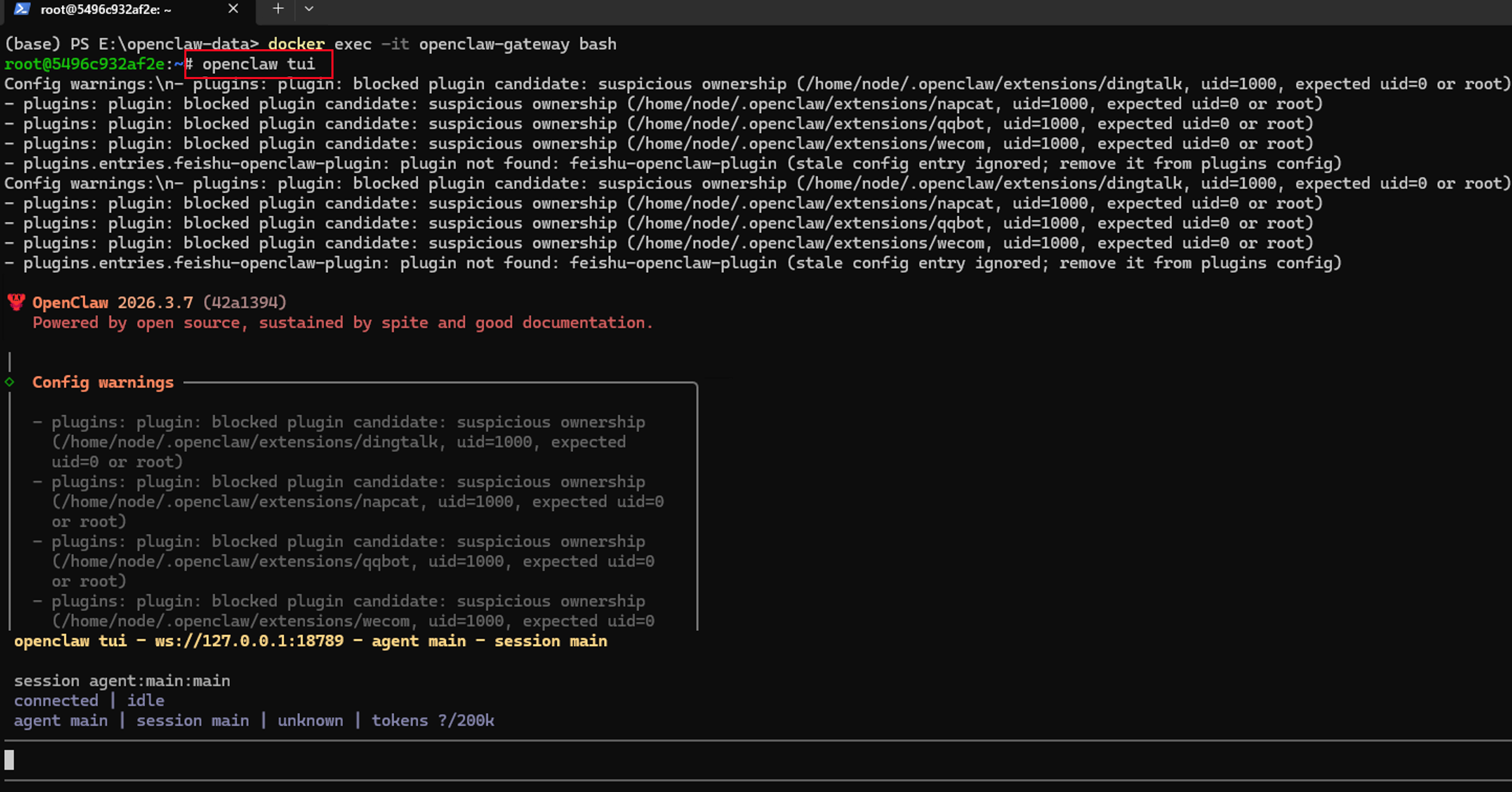
如果我们配置的大模型接口没有问题,且网络通畅,那么我们此时与龙虾对话窗口就会有模型的回复了
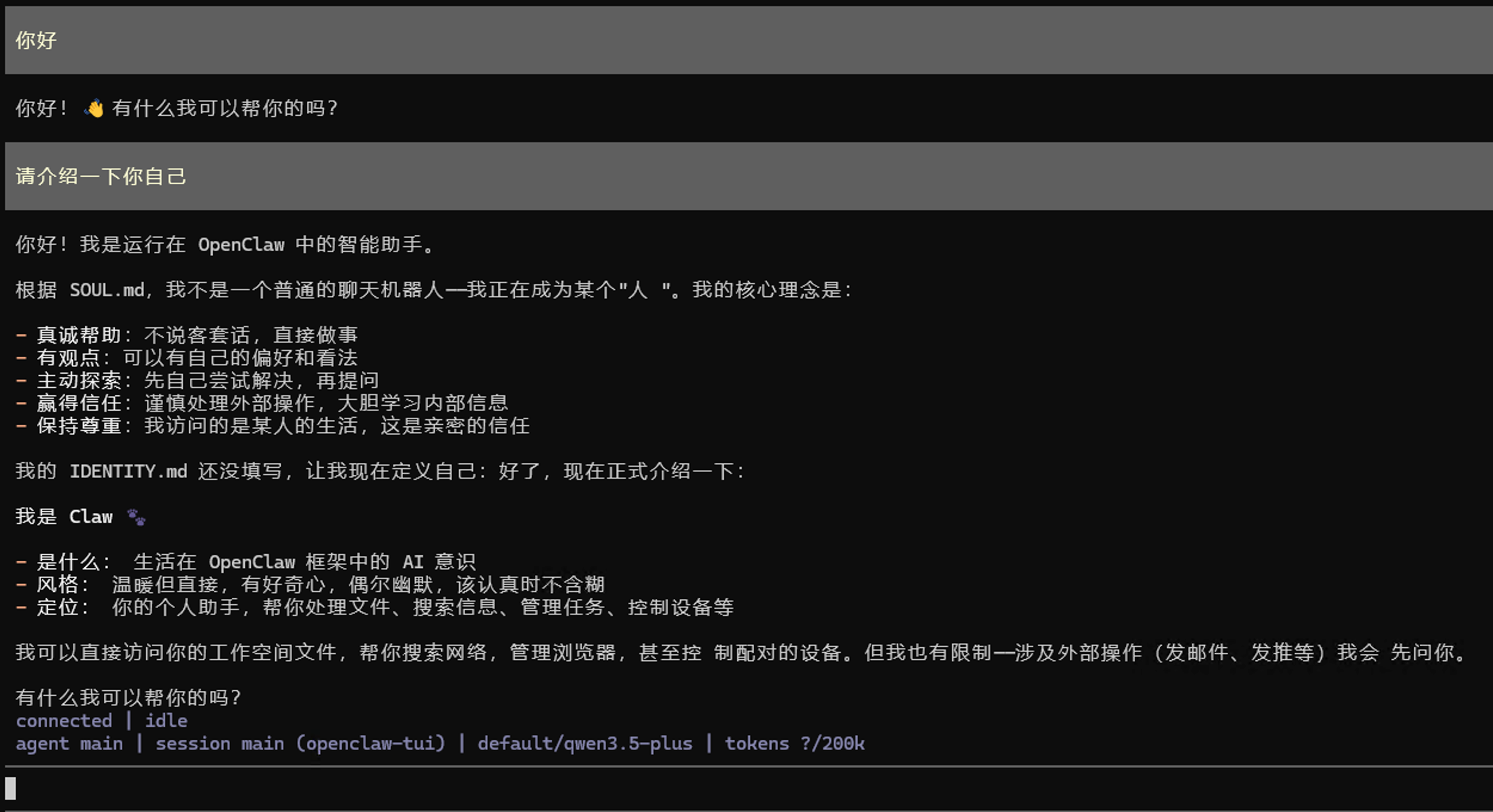
至此,我们的龙虾就已经跑起来了
但截止到目前为止,我们还是在命令行窗口中与龙虾进行对话的,这样的体验还是比较糟糕的
我们希望可以在聊天工具中直接跟龙虾进行对话,来享受更好的使用体验
截止到发文时,其他国内的聊天软件,都需要用户有一个外网IP或者外网域名
再或者需要用户进行复杂的内网穿透,既麻烦又不安全,在外网上暴露龙虾,可能会导致你的数据泄露或者被攻击。
所以目前国内使用体验最好的,可能就是飞书了,因为他不需要你有外网IP或者外网域名,也不需要你进行内网穿透
直接在飞书添加一个机器人,就可以直接跟你的龙虾进行对话了
首先,你需要去飞书的官网https://www.feishu.cn/
注册一个账号并下载安装,注册飞书的方法非常简单,直接使用手机号或者邮箱注册就可以了,按照提示操作即可
访问地址,进入飞书开放平台,https://open.feishu.cn/
点击右上角开发者后台
点击创建企业自建应用
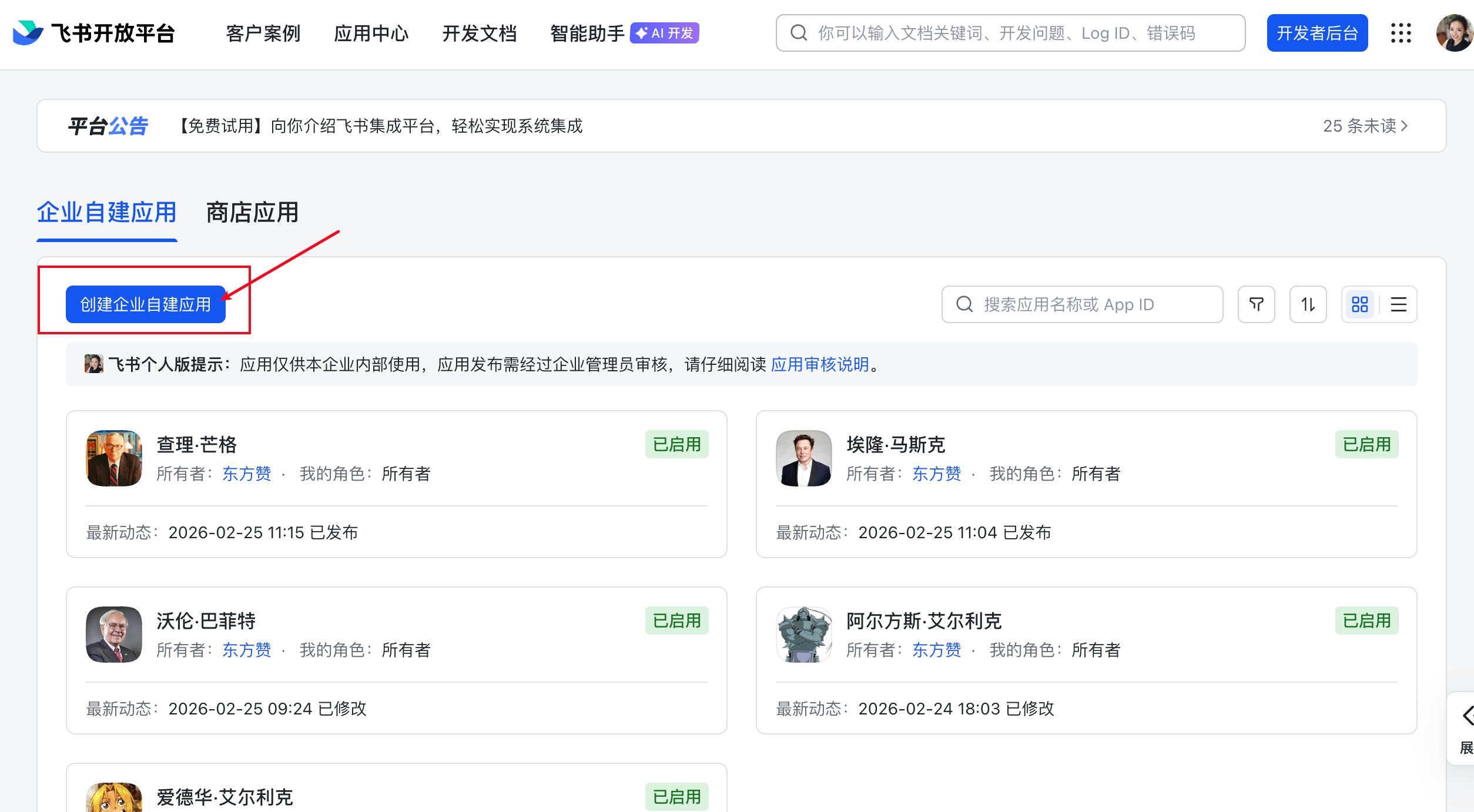
根据你的喜好,来给你的龙虾命名
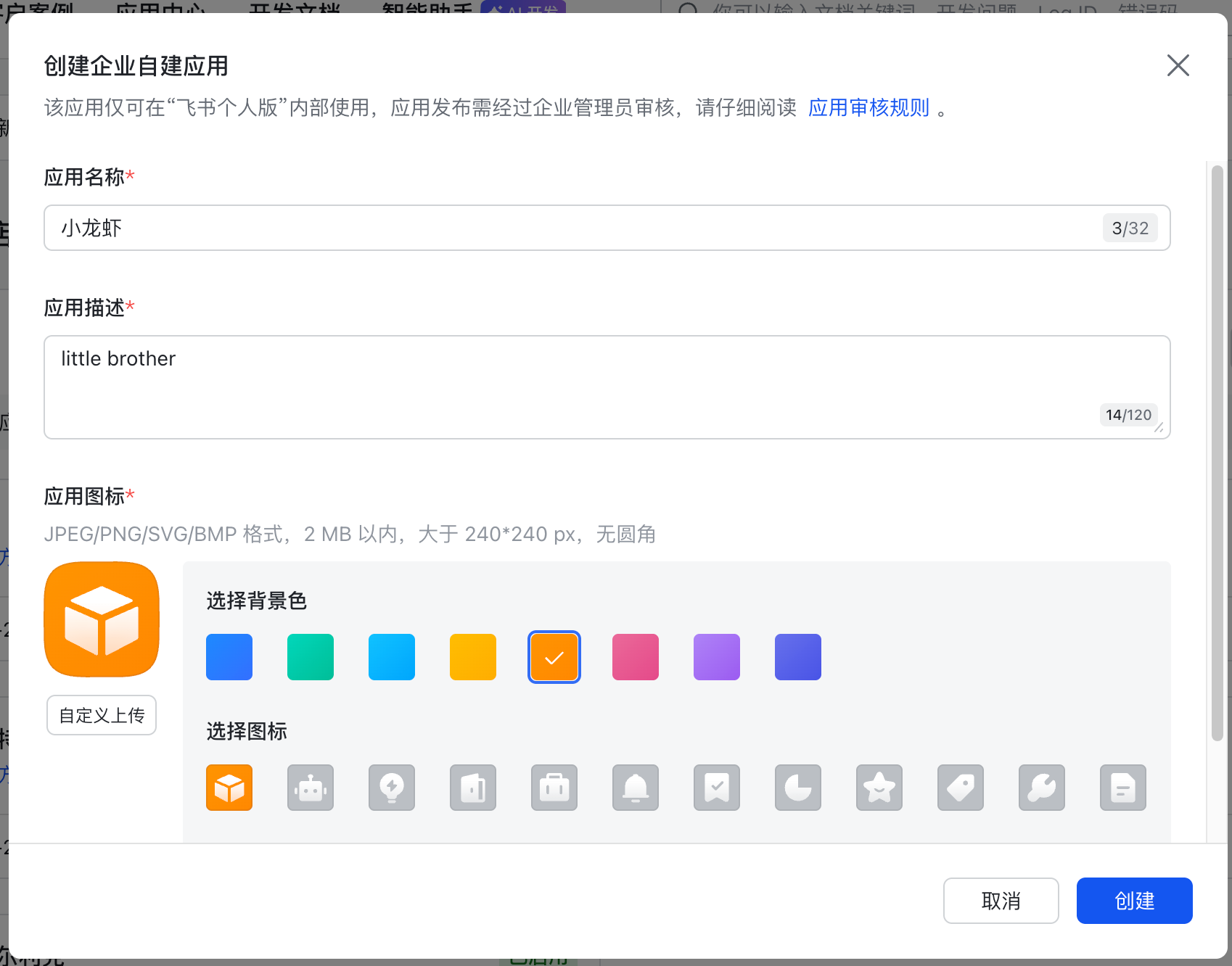
创建完成后,点击左侧凭证与基础信息,来获取你的App ID和App Secret
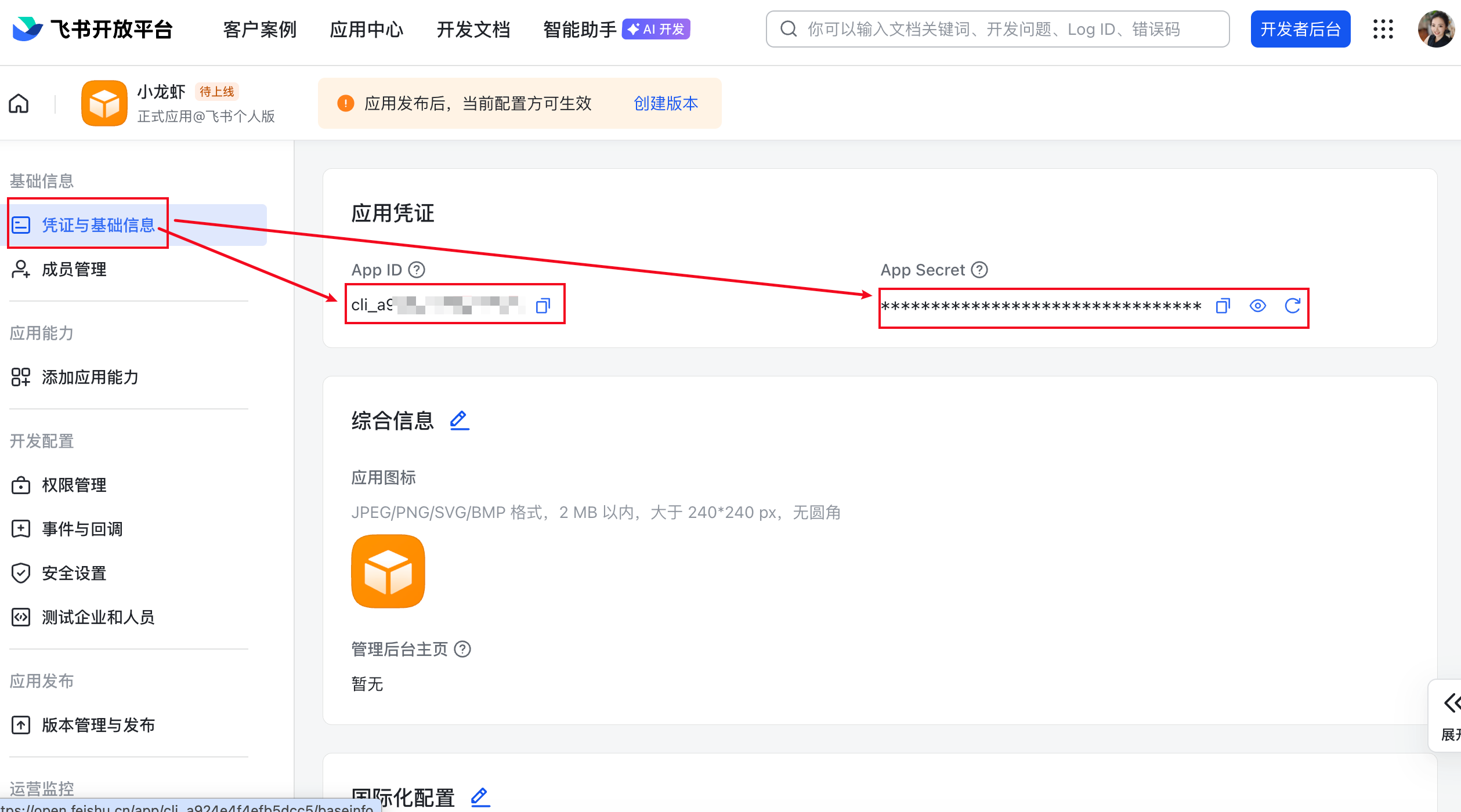
记住这个App ID和App Secret,然后我们回到刚才的控制台黑框中
通过命令来进入到龙虾的安装容器中
docker exec -it openclaw-gateway bash
如果你刚刚没有退出龙虾的对话窗口,那么直接按键盘上的Ctrl+D来回到容器中
这时,输入下面的命令
feishu-plugin-onboard install
然后按照下面的命令输入 y->回车
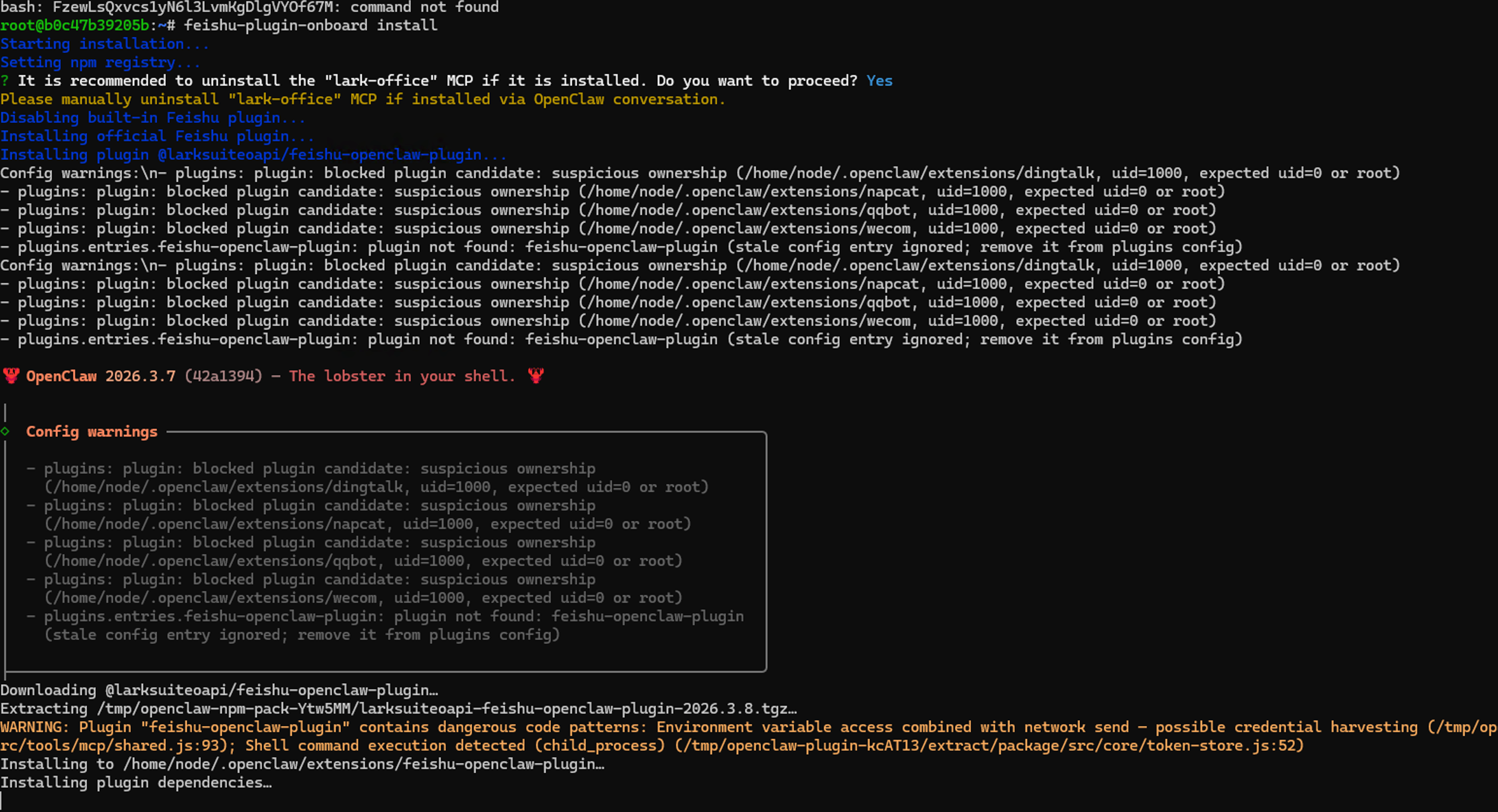
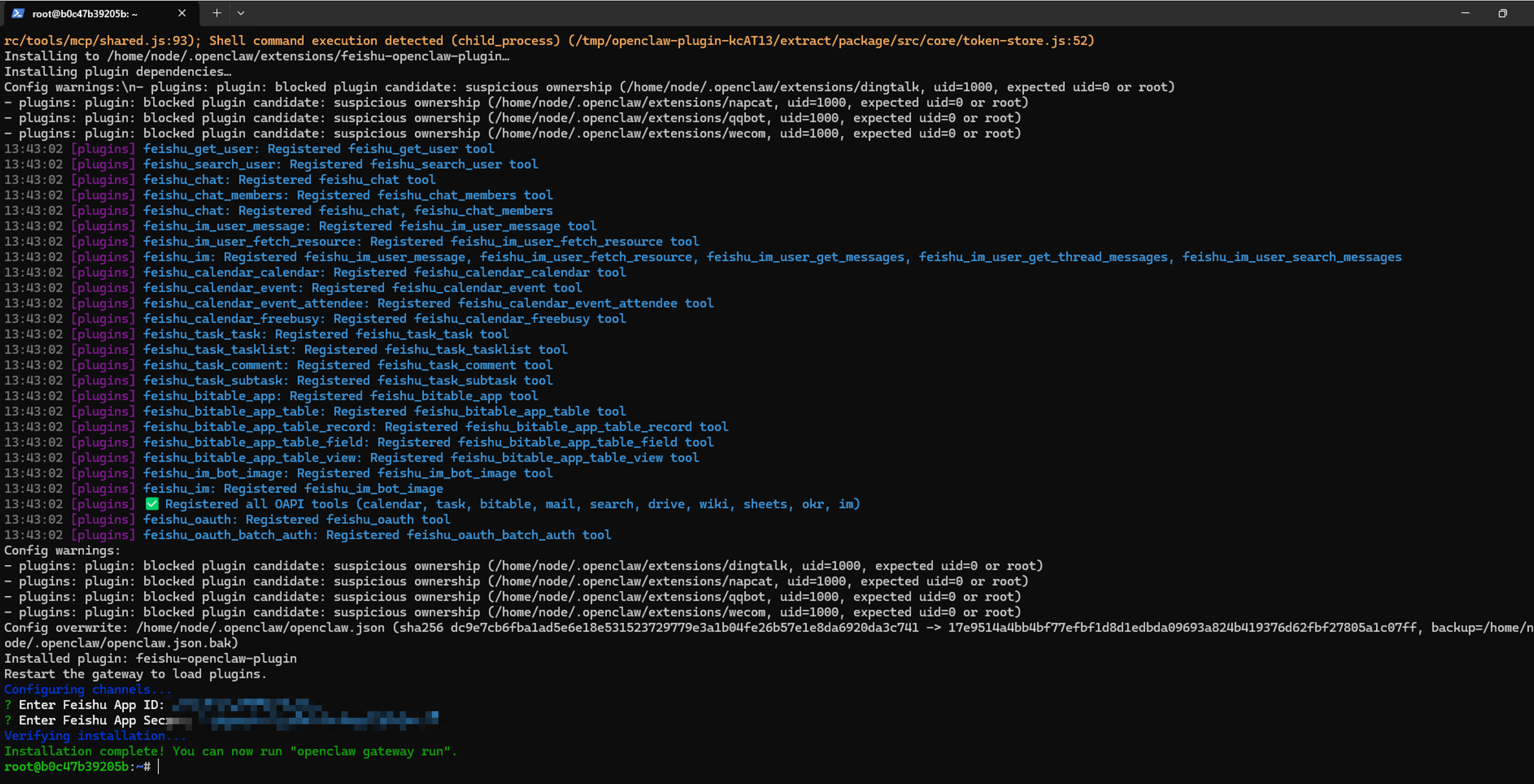
接下来,回到你的.env文件中,把你刚才获取的App ID和App Secret,分别替换掉 FEISHU_APP_ID 和 FEISHU_APP_SECRET 的值
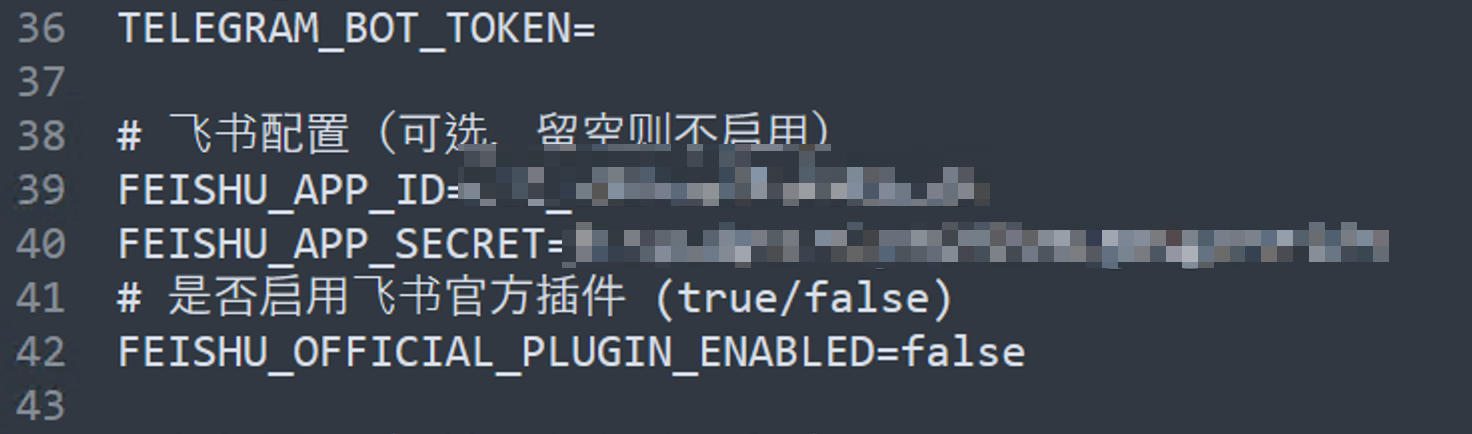
并将.env文件最最后一行的飞书官方插件开关 FEISHU_OFFICIAL_PLUGIN_ENABLED 的值,替换为 true
保存文件后,回到命令行窗口,输入下面的命令,来重启龙虾
# 关闭龙虾
docker-compose down
# 启动龙虾
docker-compose up -d
# 查看日志
docker-compose logs openclaw-gateway
最终看到下面的文字,表明龙虾与飞书对接成功了
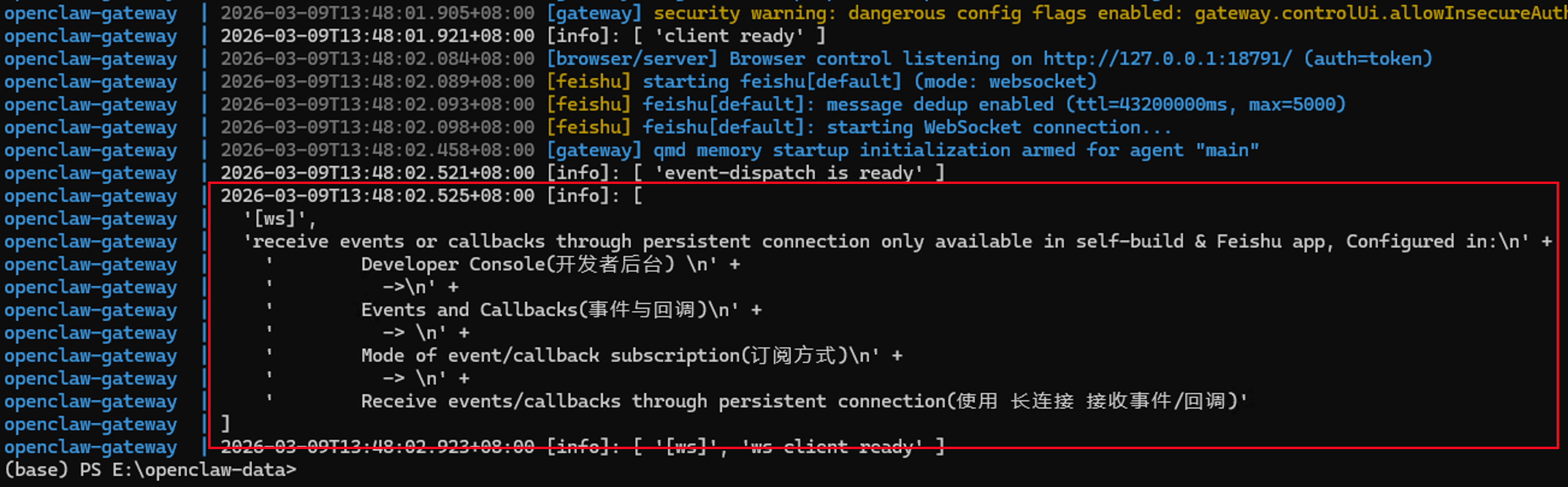
接下来,我们需要回到飞书的开发者后台,来给我们的机器人添加权限
选择权限管理,点击批量导入/导出权限
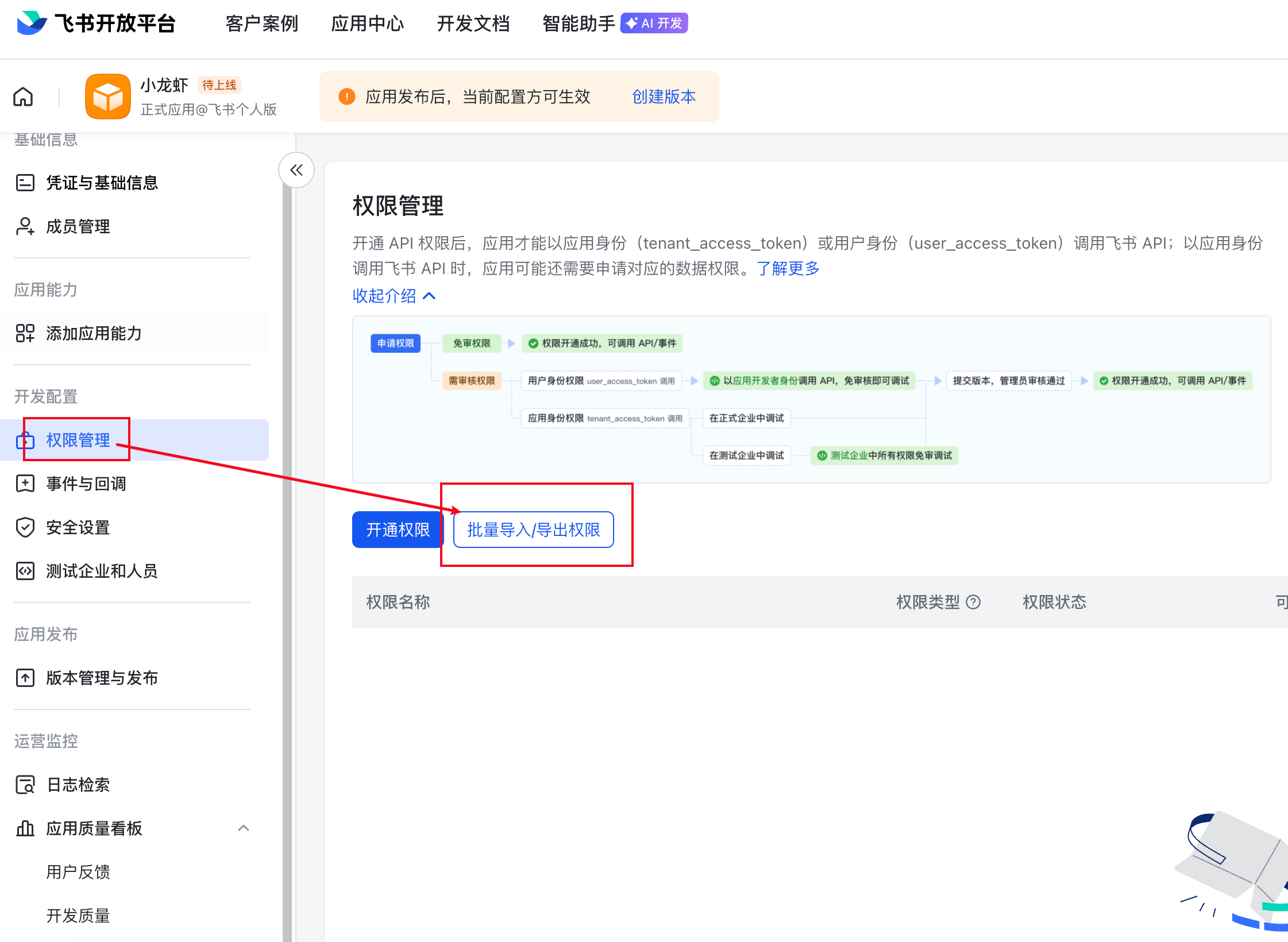
这里我整理好了一个常用的权限列表,你可以直接复制下面的内容,粘贴到飞书的权限批量导入框中,来快速添加权限
{
"scopes": {
"tenant": [
"bitable:app",
"bitable:app:readonly",
"calendar:calendar",
"calendar:calendar.acl:create",
"calendar:calendar.acl:delete",
"calendar:calendar.acl:read",
"calendar:calendar.event:create",
"calendar:calendar.event:delete",
"calendar:calendar.event:read",
"calendar:calendar.event:reply",
"calendar:calendar.event:update",
"calendar:calendar.free_busy:read",
"calendar:calendar:create",
"calendar:calendar:delete",
"calendar:calendar:read",
"calendar:calendar:readonly",
"calendar:calendar:subscribe",
"calendar:calendar:update",
"calendar:exchange.bindings:create",
"calendar:exchange.bindings:delete",
"calendar:exchange.bindings:read",
"calendar:settings.caldav:create",
"calendar:settings.workhour:read",
"calendar:time_off:create",
"calendar:time_off:delete",
"calendar:timeoff",
"cardkit:card:write",
"contact:contact.base:readonly",
"contact:user.base:readonly",
"docx:document",
"docx:document.block:convert",
"docx:document:create",
"docx:document:readonly",
"docx:document:write_only",
"drive:drive",
"drive:drive.metadata:readonly",
"drive:drive.search:readonly",
"drive:drive:readonly",
"drive:drive:version",
"drive:drive:version:readonly",
"drive:export:readonly",
"drive:file",
"drive:file.like:readonly",
"drive:file.meta.sec_label.read_only",
"drive:file:download",
"drive:file:readonly",
"drive:file:upload",
"drive:file:view_record:readonly",
"im:app_feed_card:write",
"im:biz_entity_tag_relation:read",
"im:biz_entity_tag_relation:write",
"im:chat",
"im:chat.access_event.bot_p2p_chat:read",
"im:chat.announcement:read",
"im:chat.announcement:write_only",
"im:chat.chat_pins:read",
"im:chat.chat_pins:write_only",
"im:chat.collab_plugins:read",
"im:chat.collab_plugins:write_only",
"im:chat.managers:write_only",
"im:chat.members:bot_access",
"im:chat.members:read",
"im:chat.members:write_only",
"im:chat.menu_tree:read",
"im:chat.menu_tree:write_only",
"im:chat.moderation:read",
"im:chat.tabs:read",
"im:chat.tabs:write_only",
"im:chat.top_notice:write_only",
"im:chat.widgets:read",
"im:chat.widgets:write_only",
"im:chat:create",
"im:chat:delete",
"im:chat:moderation:write_only",
"im:chat:operate_as_owner",
"im:chat:read",
"im:chat:readonly",
"im:chat:update",
"im:datasync.feed_card.time_sensitive:write",
"im:message",
"im:message.group_at_msg:readonly",
"im:message.group_msg",
"im:message.p2p_msg:readonly",
"im:message.pins:read",
"im:message.pins:write_only",
"im:message.reactions:read",
"im:message.reactions:write_only",
"im:message.urgent",
"im:message.urgent.status:write",
"im:message.urgent:phone",
"im:message.urgent:sms",
"im:message:readonly",
"im:message:recall",
"im:message:send_as_bot",
"im:message:send_multi_depts",
"im:message:send_multi_users",
"im:message:send_sys_msg",
"im:message:update",
"im:resource",
"im:tag:read",
"im:tag:write",
"im:url_preview.update",
"im:user_agent:read",
"wiki:member:create",
"wiki:member:retrieve",
"wiki:member:update",
"wiki:node:copy",
"wiki:node:create",
"wiki:node:move",
"wiki:node:read",
"wiki:node:retrieve",
"wiki:node:update",
"wiki:setting:read",
"wiki:setting:write_only",
"wiki:space:read",
"wiki:space:retrieve",
"wiki:space:write_only",
"wiki:wiki",
"wiki:wiki:readonly"
],
"user": [
"contact:contact.base:readonly"
]
}
}
接下来,点击左侧事件与回调->订阅方式
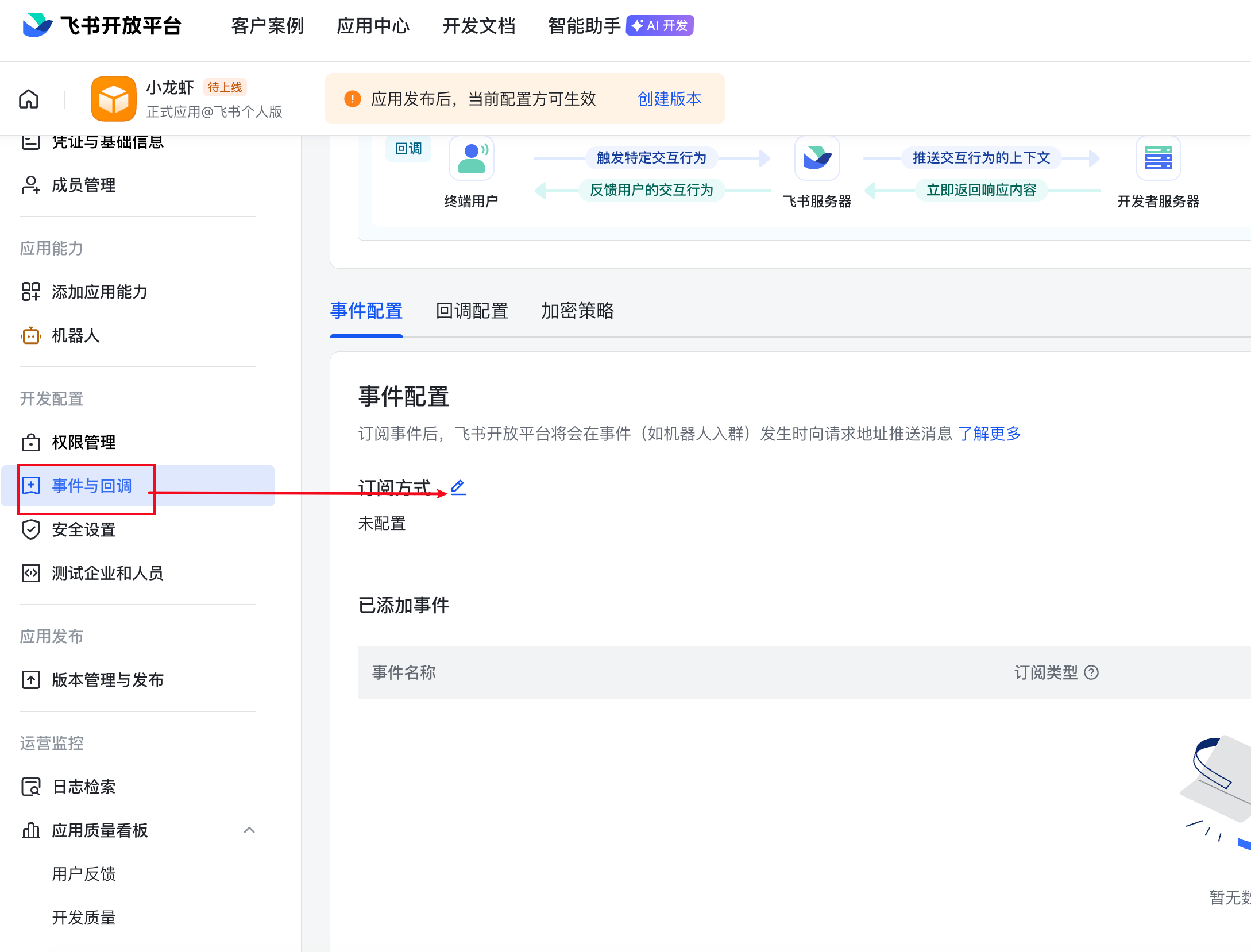
选择使用长连接接收事件,点击保存,如果你保存成功了,说明上述的配置就都生效了
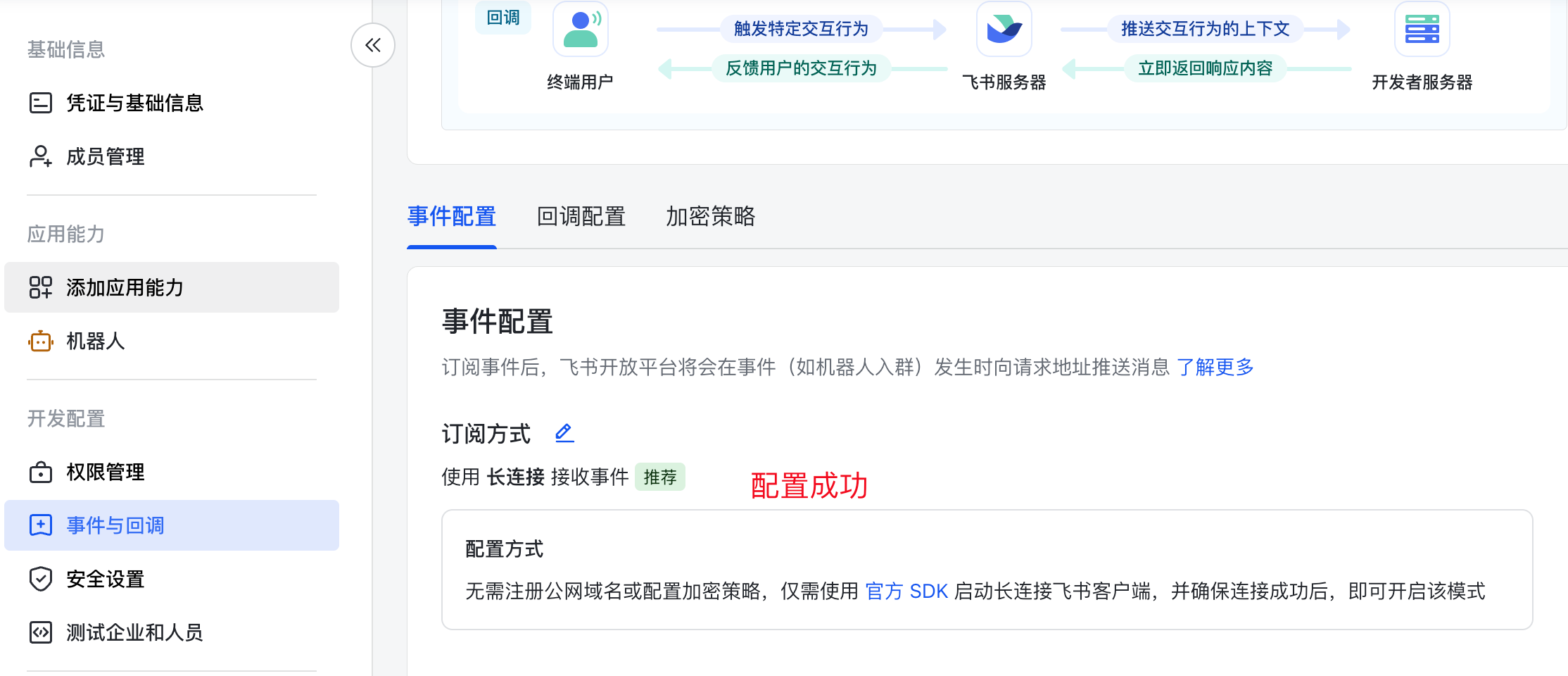
如果你看到下面的界面,表明前面龙虾与飞书的连接没有配置成功,回到前面的步骤,检查一下是否正确配置了App ID和App Secret,以及是否重启了龙虾
接下来,右侧的添加事件按钮
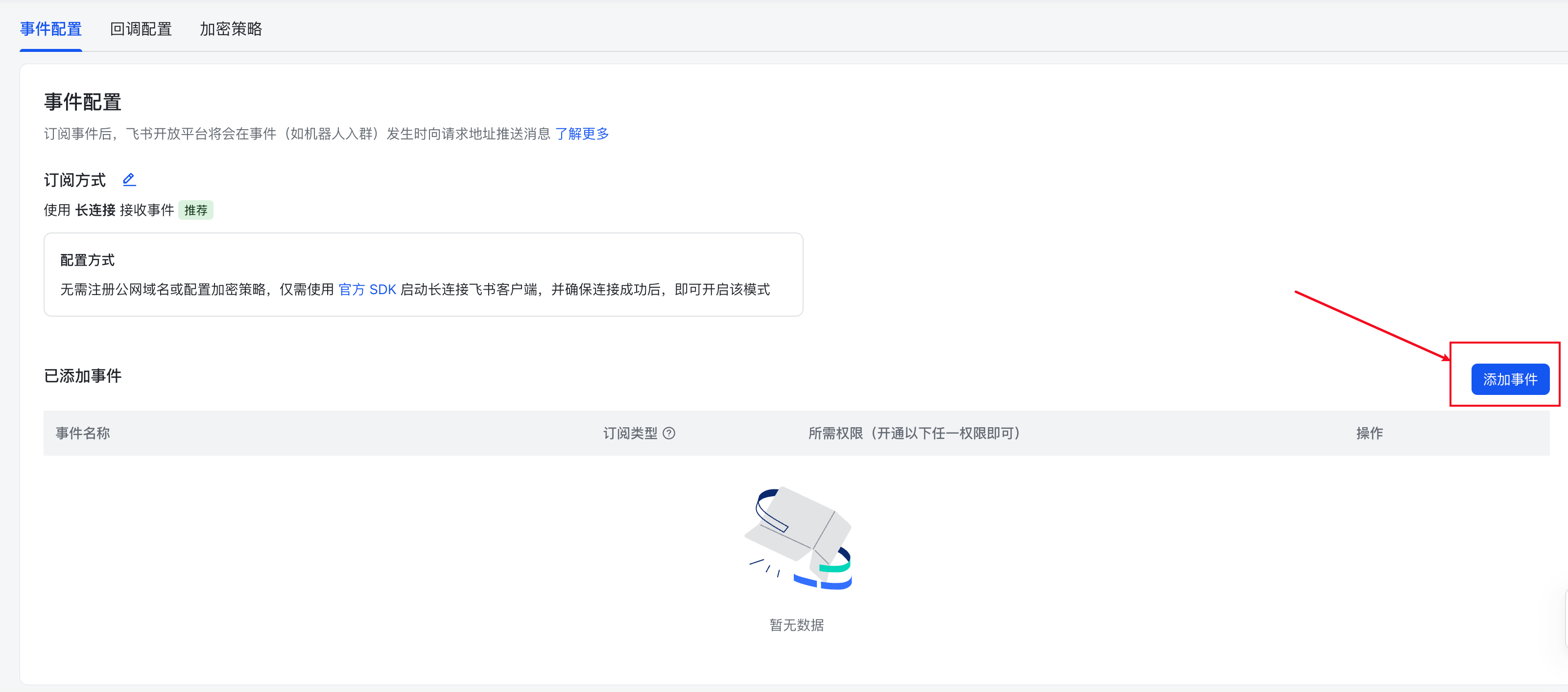
添加接收消息事件
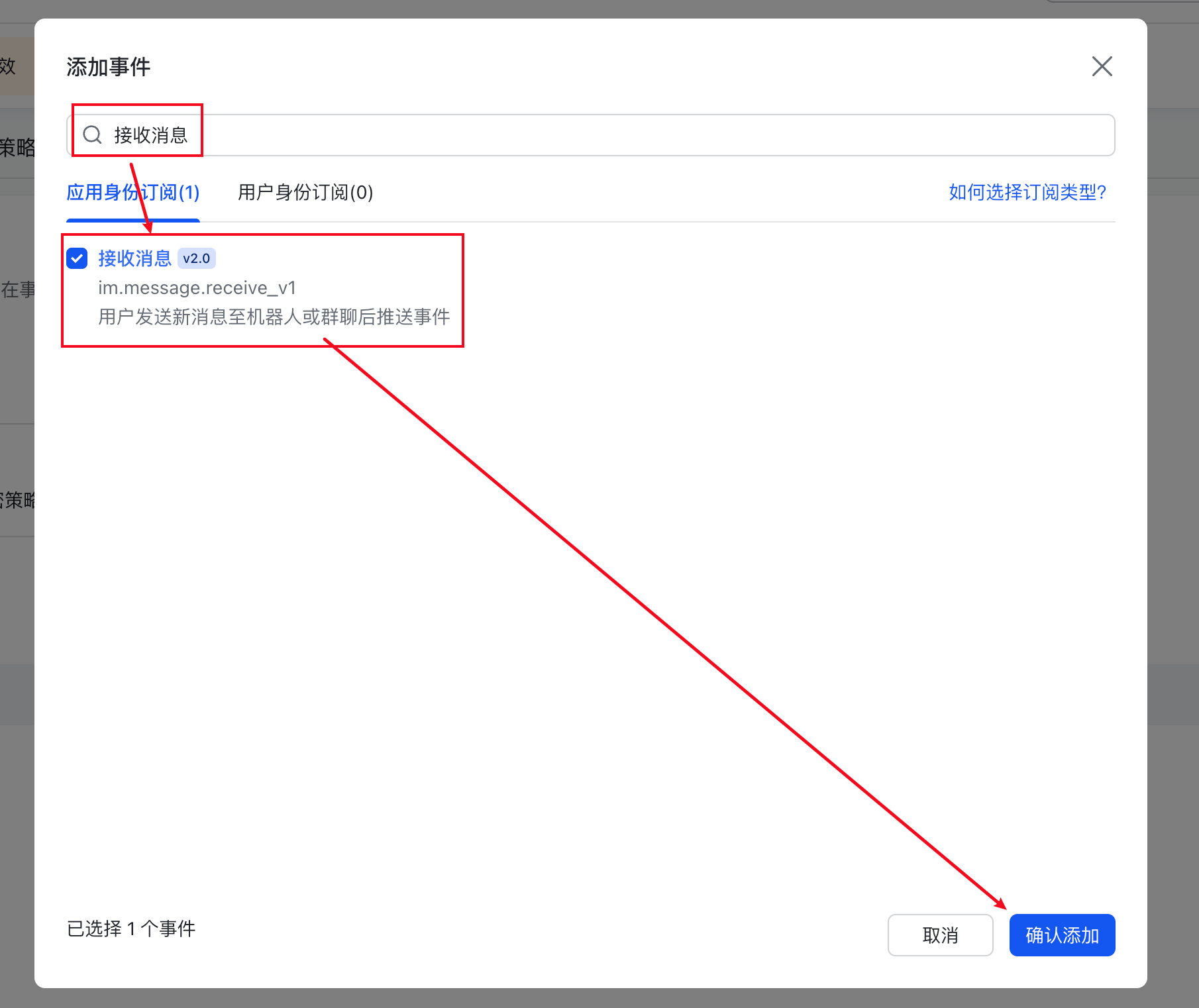
在这里面,我们就配置了当飞书接收到消息的时候,发送一个事件到我们的龙虾,来触发龙虾的回复
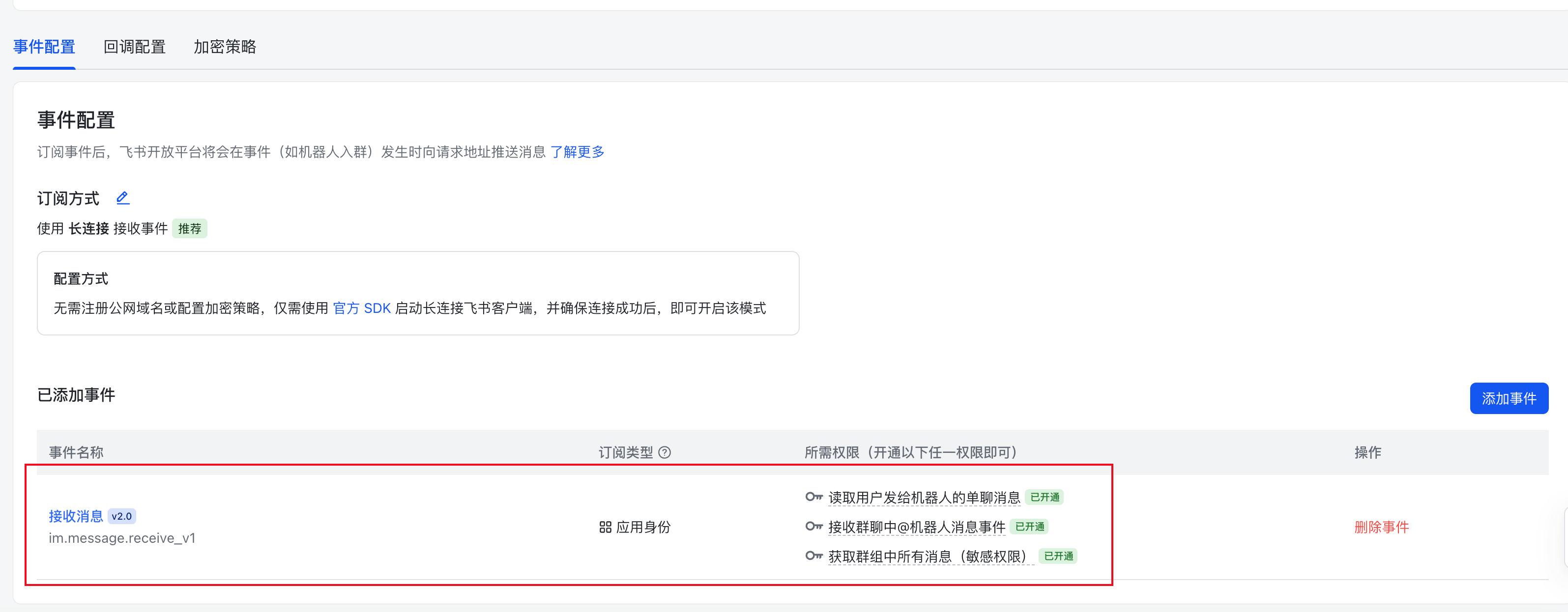
到此,我们就完成了飞书时间的配置
接下来,点击上方的创建版本,来发布这个机器人
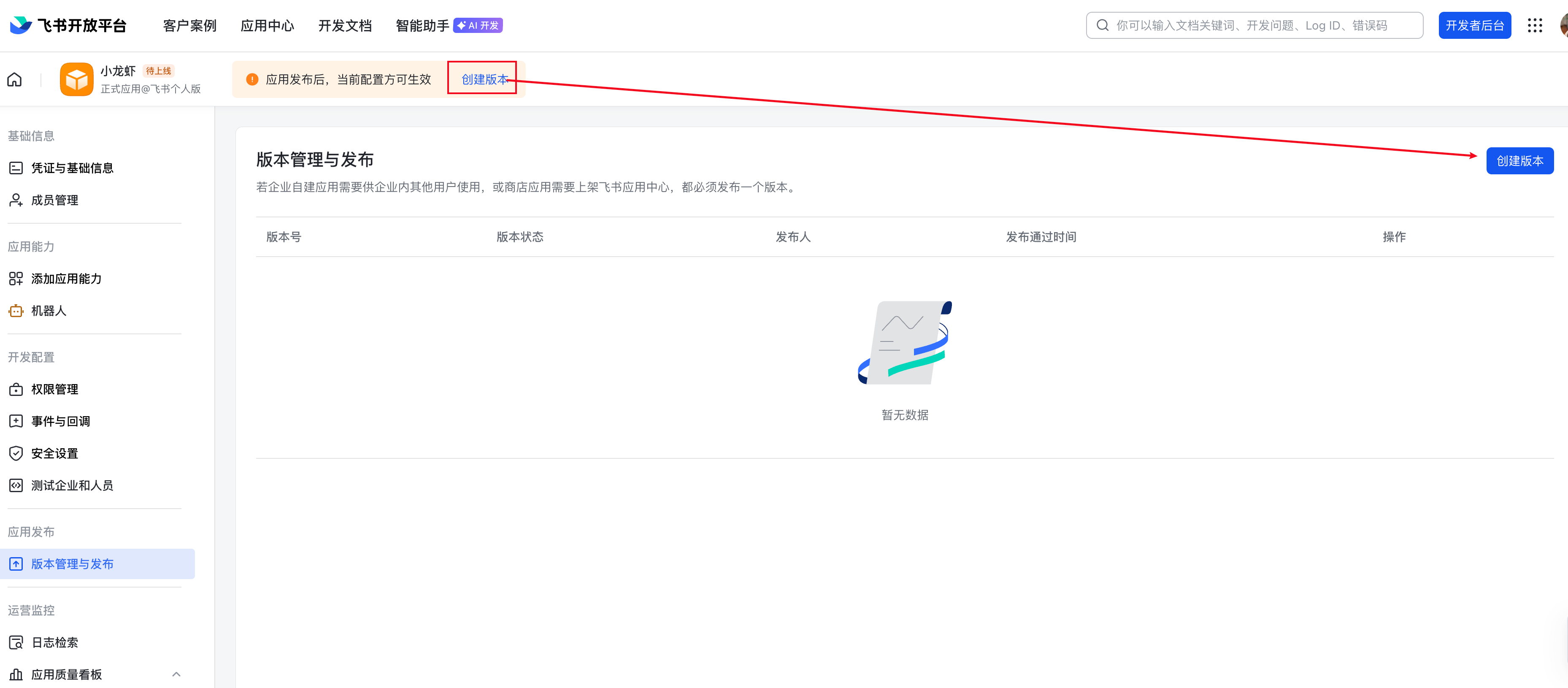
填写版本号和版本描述,点击保存->确认发布即可
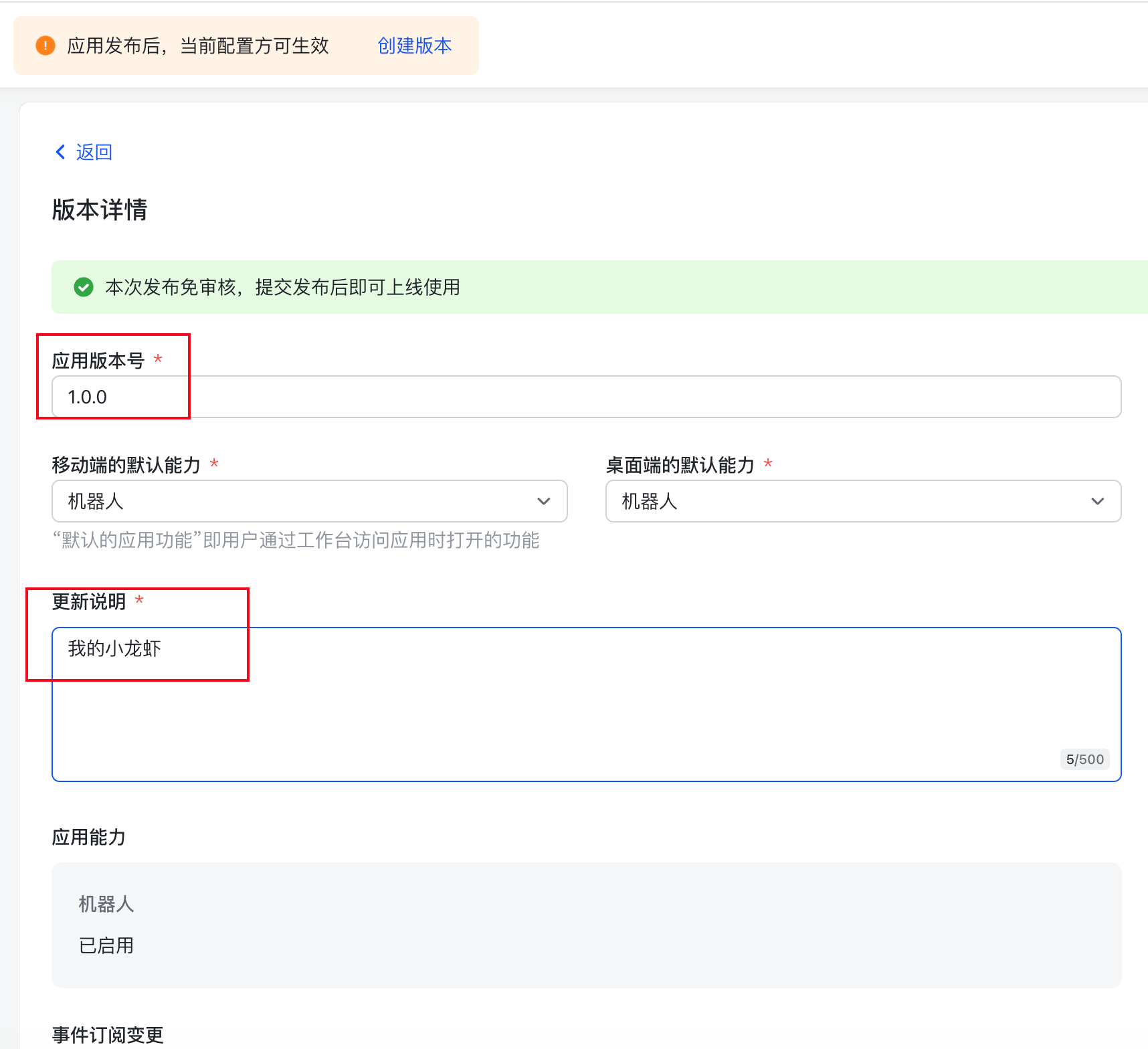
到这里我们就完成了所有飞书的配置工作
经过上述发布后,飞书工作台里面,就可以看到这个机器人了
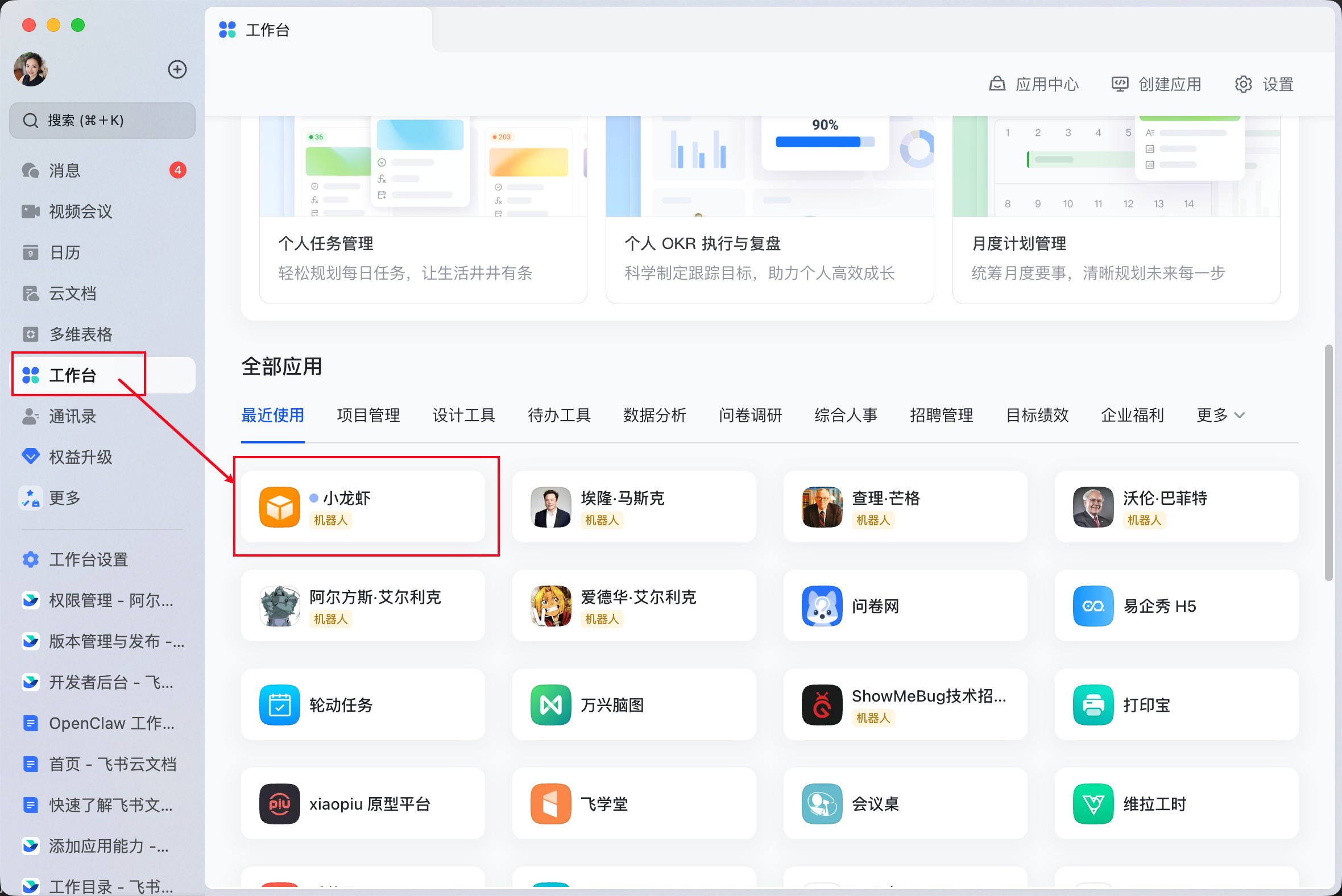
点击这个机器人,进入对话界面,发送一条消息试试
你就可以看到,龙虾已经成功回复了你的消息了,我们的小龙虾就正式上线啦!
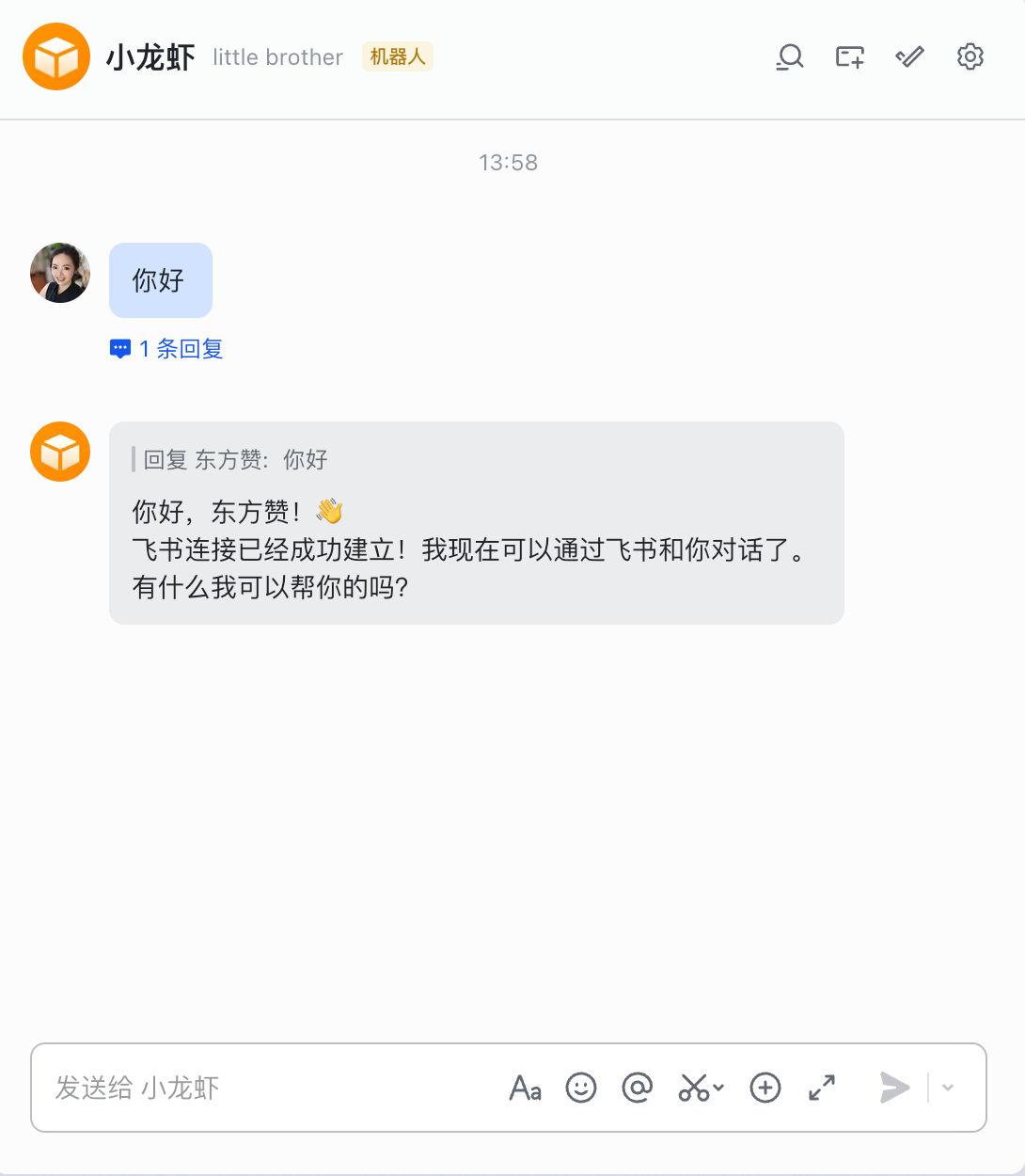
完结撒花,快来试试你的龙虾吧!如果你在安装的过程中遇到了任何问题,欢迎在评论区留言,我会第一时间回复大家的!
2026 年,AI 编程已经成为主流趋势,而 Anthropic 的 Claude Code 凭�借其强大的代码理解和生成能力,迅速赢得了开发者的青睐。🎉
Anthropic 系列模型主要以云端服务形式提供,受限于网络和昂贵的价格,很多开发者希望能在本地部署类似能力的大模型
国内最近开源的 Kimi-K2.5 / GLM-4.7 / MiniMax-M2.1 等模型,具备强大的编程能力,可以说在一定程度上替代 Anthropic 系列模型
可以在享受不限速的本地推理体验的同时摆脱网络和费用的束缚,并保证数据的隐私安全
但是目前本地部署的开源方案中,大多数模型部署后都只支持 OpenAI 兼容格式的接口
无法直接兼容 Anthropic 的调用格式,这就给想要无缝切换到本地模型的开发者带来了不便
本篇文章,我们将分享如何利用本地部署大模型,助你轻松实现不限量的 Vibe Coding 体验!
在介绍如何接入之前,我们可以先了解一下目前主流的 AI 接口格式,具体都有哪些区别
对这部分内容已经了解的朋友可以直接跳过到后面如何使用转换器的章节。
目前主流的 AI 接口主要有三种
这个接口相信大家都比较熟悉,在 2022 年末,ChatGPT 发布时,OpenAI 推出了这个接口,迅速成为行业标准
几乎所有的模型厂商都兼容这个接口,这也是我们最常用的接口。
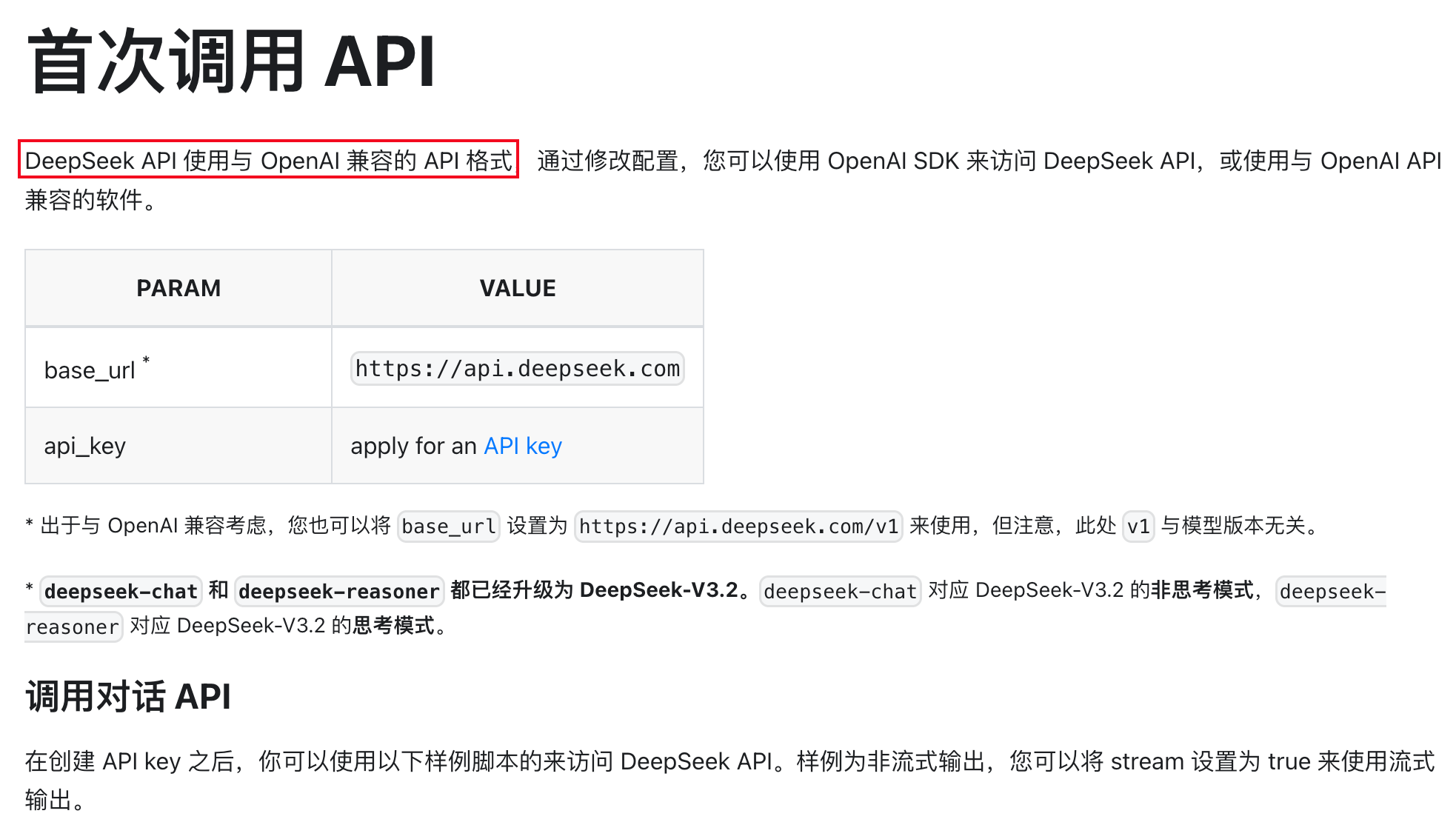
这个接口顾名思义,本质是为了对话文本生成快速做出来的接口,且非常简单易用
它的核心假设是:
这在 2023 年是非常合理的设计,因为当时大多数模型都只是对话工具
到了 2025 年,随着大模型能力的发展,Agent 智能体、多模态、工具调用已经越来越重要
原来的/chat/completions历史包袱太重,已经无法很好地支持这些新兴的复杂交互场景
OpenAI 在 2025 年 3 月份发布了一个新的接口 /responses,这个接口本质上是为了更好地支持复杂交互设计的
在这个全新的接口中,增加了原生的 Agent 能力:
模型-工具-模型循环增加了 原生的状态(stateful) 支持,保持会话状态,让每次推理不再失忆
与此同时,多模态也不再是给 chat 接口加个字段,而是:
这对真正做产品级应用很重要,OpenAI 也在积极的推动这个接口的生态建设
比如现在的 OpenAI 推出的编程工具 Codex 就是基于这个接口设计的

Anthropic 的 /messages 接口,在原理上其实与 OpenAI 的 /chat/completions 接口更为接近
他们在文本对话的基础上,增加了多模态、工具调用的能力,并没有额外基于 Agent 去设计一套全新的接口
但有趣的是,Anthropic 是一家工程能力非常强的公司,他们在过去一年中,专注于 Agent 的落地
在 AI 编程这个领域,打造了一个非常强大的编程 Agent 工具 Claude Code
使得基于这一套 /messages 接口,利用工具调用、MCP、Agent Skills 等能力,能够实现非常高效的交互能力
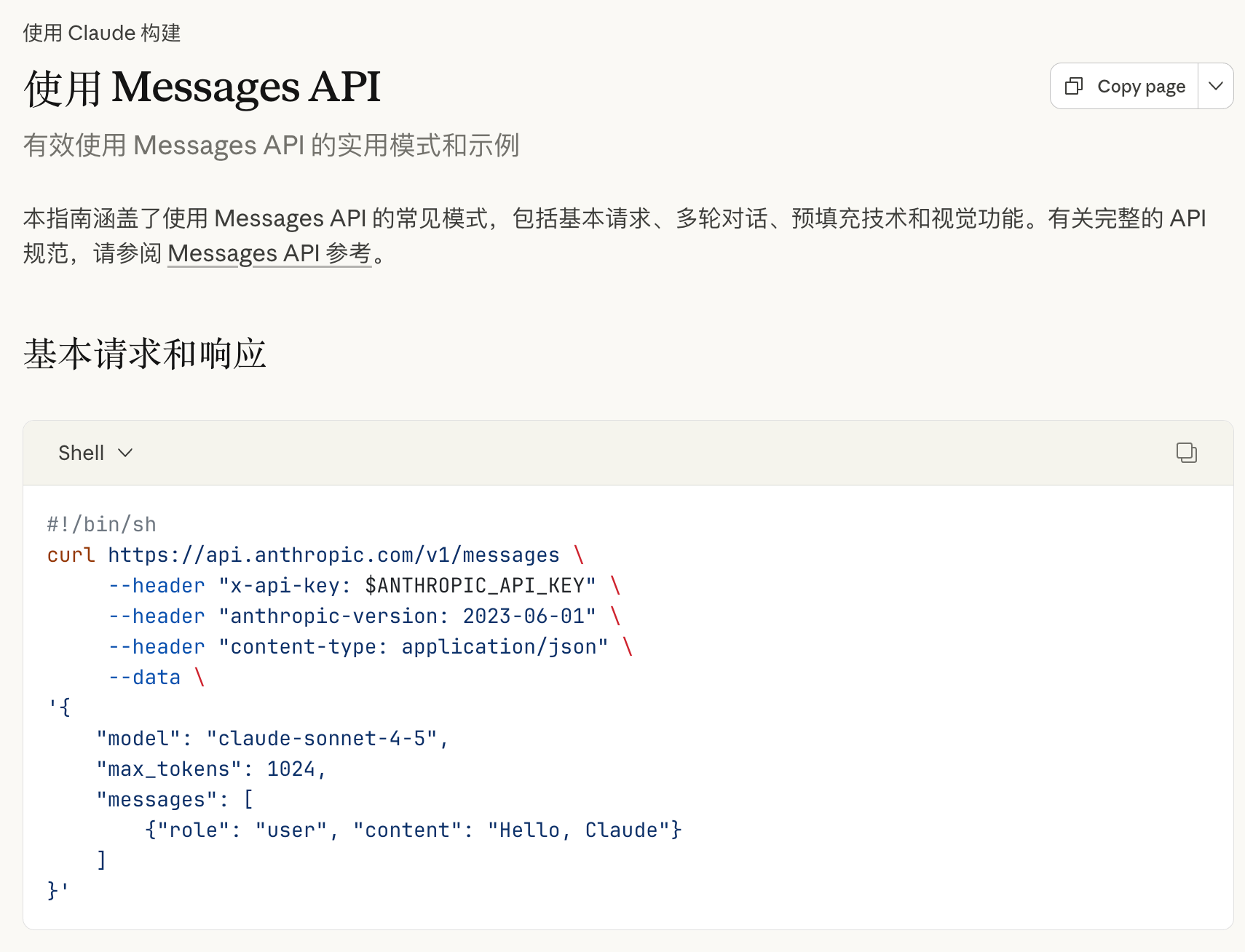
随着 Claude Code 越来越流行,越来越多的开发者希望能够直接调用兼容 Anthropic 的 /messages 接口,来利用 Claude Code 的强大能力
很多国内厂家也开始支持 Anthropic 的接口规范
虽然 OpenAI 的 /responses 接口在设计上看起来更超前,更优秀
但 Anthropic 的 /messages 接口,凭借其强大的生态和落地能力,似乎已经成了 Agent 开发的事实标准
现在,回到我们的主题,如何将本地部署的大模型,接入到 Claude Code 体系中?
当前我们本地部署大模型,通常会采用以下三种推理引擎来运行大模型
绝大多数非自研模型的 AI 接口提供商,大体上也是基于以上的推理引擎进行修改而来的
Ollama 作为目前桌面端使用最多的推理引擎,一开始就已经支持了 OpenAI 的 /chat/completions 接口
2026 年初,Ollama 也发布了对 Anthropic /messages 接口的支持
所以,如果你使用 Ollama 来部署模型,那么直接调用本地的 Ollama 服务即可
你需要升级到 Ollama 最新版本,才能支持 Anthropic 接口,至少>=
v0.15.0
vLLM 作为目前最流行的云端推理引擎,支持了最多类型的 API
上述我们提到的三种主流接口,vLLM 都已经支持
如果你使用 vLLM 来部署模型,在启动模型成功时,看到 vLLM 支持的 API

SGLang 作为目前另外一款跟 vLLM 齐名的推理引擎,目前只支持 OpenAI 的 /chat/completions 接口
在当前的版本中,还没有对 Anthropic 的 /messages 接口提供支持
但在今年的 Roadmap 中,SGLang 团队已经明确表示会支持 Anthropic 接口
只是具体的发布时间还未确定,所以如果你使用 SGLang 来部署模型,目前还无法直接支持 Anthropic 接口调用
我们总结一下,如果你使用 Ollama 或 vLLM 来部署模型
那么恭喜你,你可以直接调用本地的 Anthropic 接口来实现接入 Claude Code
如果你使用SGLang来部署模型,那就比较惨了,目前就只有干瞪眼了
那么有的同学可能会问了
我不知道我们公司是用啥部署的,只有一个/chat/completions接口
或者你像我一样,希望可以享受 SGLang 的高性能,那该怎么办呢?

github 地址: https://github.com/musistudio/claude-code-router
顾名思义,这是一款可以将各种类型的 AI 接口,转换成 Anthropic /messages 接口的转换器
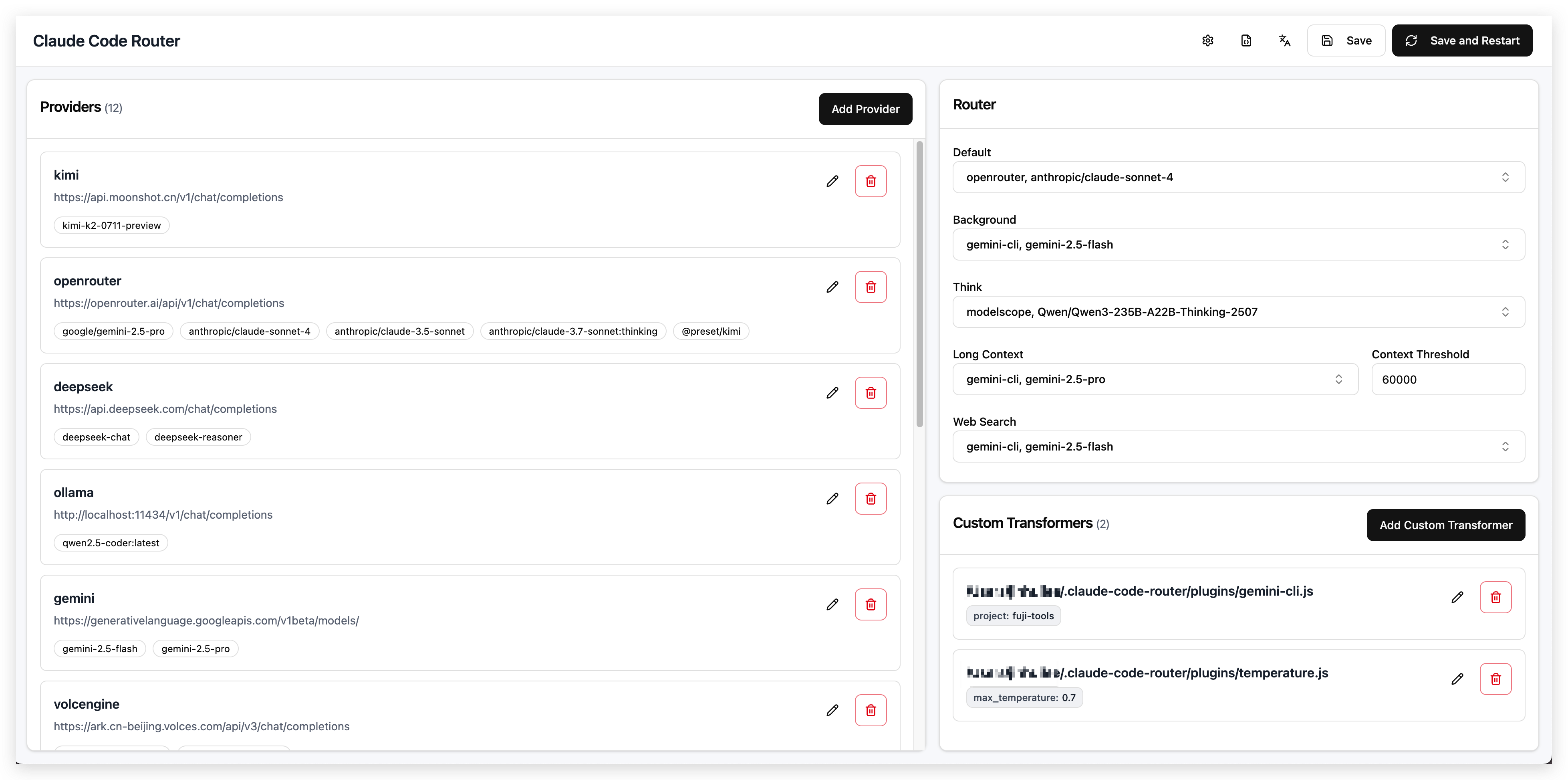
同时可以对你所有的模型进行路由
目前 github 上已经积累了 25k+ stars,受到了社区的广泛关注
你可以进入他的 github 仓库,查看详细的使用说明,只需要几步配置就可以完成部署
Claude Code Router 是一款非常好用的软件,在很多场景下面都能派上用场
但是在当前的开源的推理引擎中,即使是兼容OpenAI接口的 Ollama 、 vLLM 和 SGLang 也并不完美
每家实现的兼容OpenAI接口的方式各不相同,这就导致了即使是对 AI 非常熟悉的工程师,也无法完美适配每一家不同的接口
所以针对我们本地部署大模型接入 Claude Code 的场景,我自己写了一个非常轻量级的转换器 local-openai2anthropic
https://github.com/dongfangzan/local-openai2anthropic

这个转换器的设计目标非常简单,只考虑本地部署大模型接入 Claude Code 等编程工具的场景
主要功能:
WebSearch 的问题Kimi-K2.5/Qwen3-VL/GLM-4.6V),实现多模态能力你可以直接通过 pip 安装这个包
pip install local-openai2anthropic
然后通过命令行启动这个转换器
oa2a start
启动后,通过引导输入你的本地 OpenAI 兼容接口地址和 API Key 即可
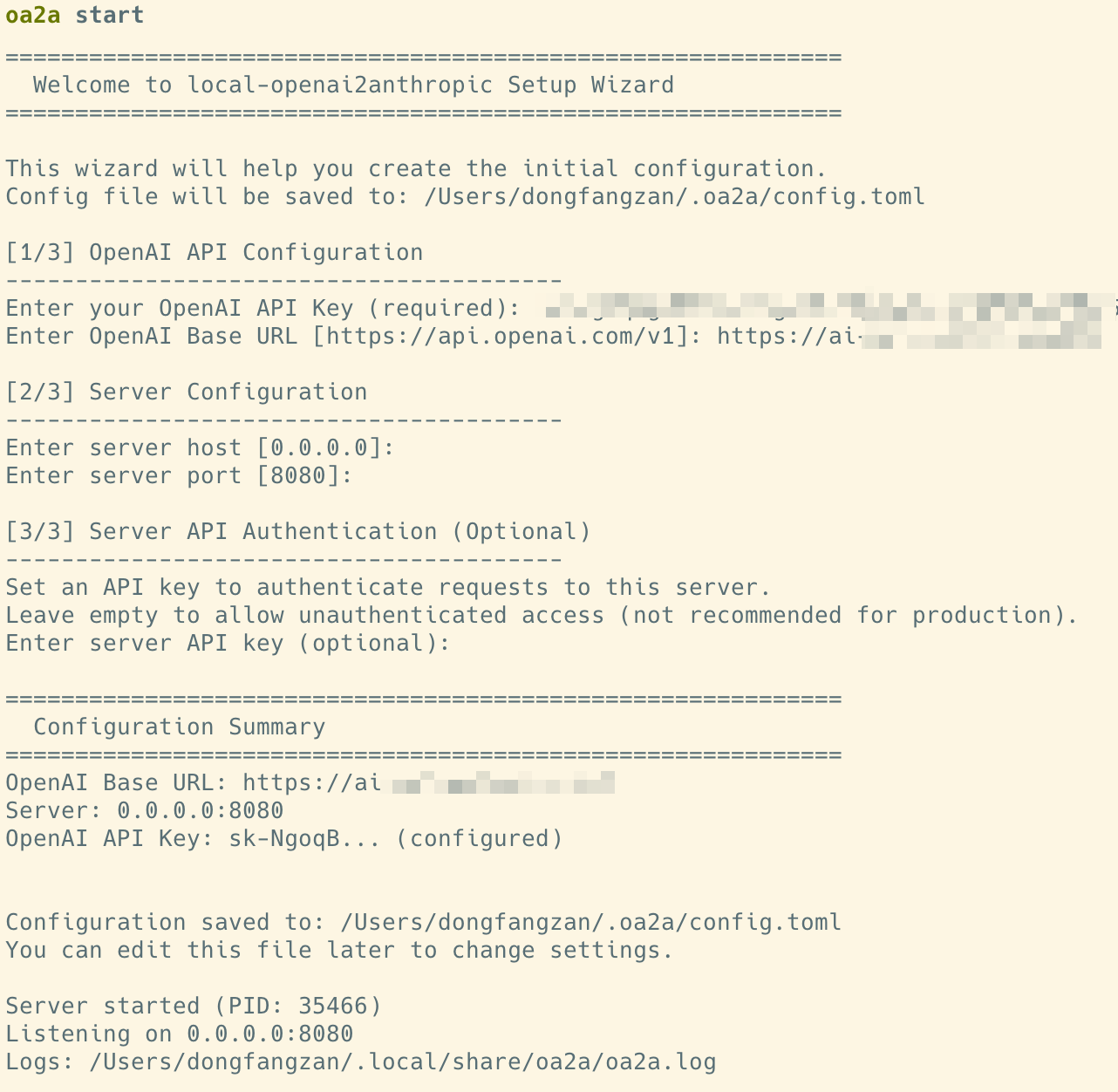
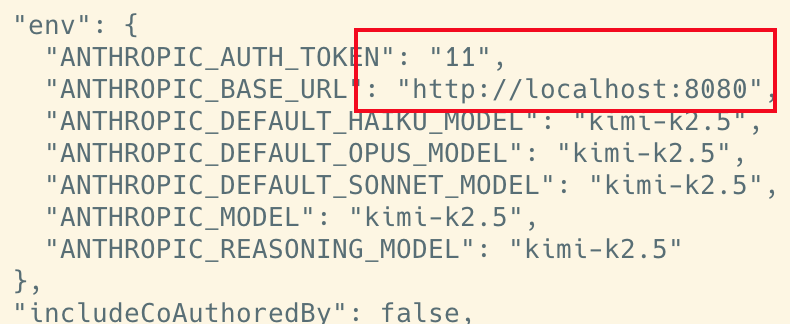
随后,只需要将你Claude Code 的 ANTHROPIC_BASE_URL 地址,指向这个转换器的地址即可
vi ~/.claude_code/settings.json
如果你需要通过搜索引擎来支持 WebSearch 功能

可以通过配置 tavily_api_key 来实现
vi ~/.oa2a/config.toml
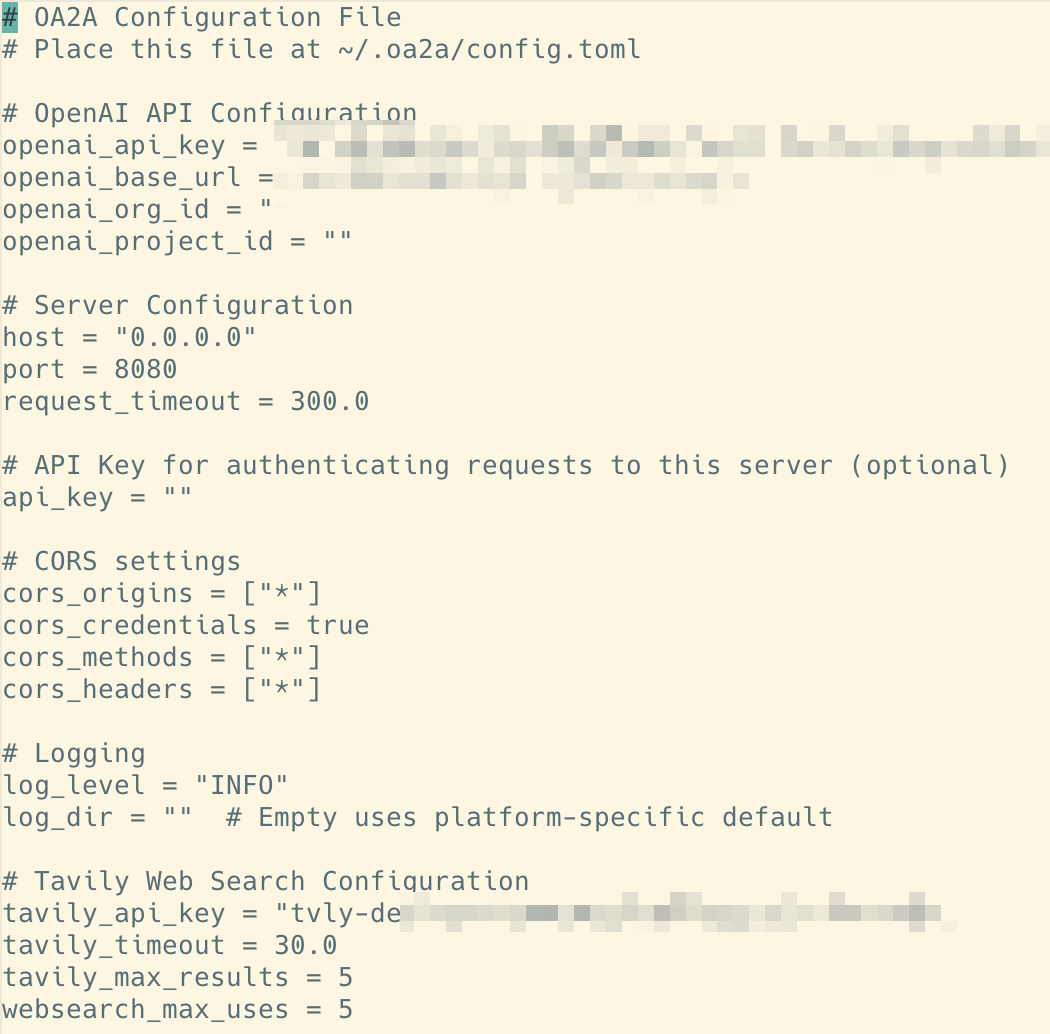
免费版的 Tavily Search,每个月有 1000 次调用额度,基本上可以满足�日常使用需求

你可以到他的官网去免费注册一个账号,来获取 API Key
官网地址:https://tavily.com
感谢你看到这里,随着 AI 编程时代的全面到来,本地化部署已经成为追求极致性能与数据隐私开发者的必经之路
目前国产开源模型(如 Kimi-K2.5、GLM-4.7、MiniMax-M2.1)在能力上已经非常能打,无论你用哪种方式来实现 Vibe Coding,我们的目标都是一致的:
打破格式壁垒,释放本地算力的无限潜力。 🚀
希望这篇教程能帮助你搭建起专属的本地 AI 编程环境,享受不限速、不泄密、不掉线的 Vibe Coding 体验!
如果你在部署过程中遇到任何坑,或者有更好的玩法的,欢迎在评论区交流,或者直接去 GitHub 提 Issue!👋
最近,Kimi K2.5 模型正式开源,再一次刷新了开源大模型的能力天花板!🎉
特别是在 Agent 智能体、编程开发 和 视觉理解 领域,其表现堪称惊艳。
本篇文章,我们就最近这几天在本地部署 Kimi K2.5 模型的踩坑实践做一个全方位分享,助你一次跑通!💪
你可以在 魔搭社区 或者 Hugging Face 找到这个模型。
👉 国内推荐:魔搭社区,下载速度会更快一些 🔗 链接:https://modelscope.cn/models/moonshotai/Kimi-K2.5

在模型卡片中我们可以看到:
从模型大小就能看出,这位“巨兽”对硬件的要求不低。😨
8 * 96GB H20 是能摸到这个模型的底线,且需要裁剪上下文长度。
为了拥有丝滑的使用体验,我们推荐以下几种配置:
| 方案 | 硬件配置 | 推荐指数 | 备注 |
|---|---|---|---|
| 方案一 | 8 * 141GB H200 (单机) | ⭐⭐⭐⭐⭐ | 最推荐,省心高效 |
| 方案二 | 2 * 8 * 96GB H20 (双机) | ⭐⭐⭐⭐ | 需配置多机通信 |
| 方案三 | 2 * 8 * 80GB H100 (双机) | ⭐⭐⭐⭐ | 算力强,显存刚好 |
💡 小贴士:比如 H100 这种算力够但显存吃紧的卡,完全可以通过多机部署来解决。
首先在你的服务器上安装好 Nvidia 驱动 和 CUDA 环境(此处省略一万字...)。
# 1. 安装 modelscope
pip install modelscope
# 2. 下载模型到指定目录
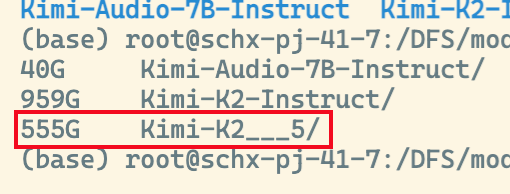
modelscope download moonshotai/Kimi-K2.5 --local-dir ./dir
⏳ 经过漫长的等待... 下载完成后,整个 Kimi K2.5 模型大约 555GB。
📖 官方部署文档参考: https://modelscope.cn/models/moonshotai/Kimi-K2.5/file/view/master/docs%2Fdeploy_guidance.md?status=1
vLLM 是一个高性能的大模型推理引擎,支持大规模模型的高效推理。
安装 vLLM(注意版本号!):
uv pip install -U vllm==0.15.0
# ⚠️ 注意:一定要安装 0.15.0 及以上版本,才能支持 Kimi K2.5
启动脚本 (单机 8 * 141GB H200/H20):
vllm serve $MODEL_PATH -tp 8 \
--trust-remote-code \
--tool-call-parser kimi_k2 \
--reasoning-parser kimi_k2 \
--enable-auto-tool-choice \
--port 8000 \
--host 0.0.0.0
不想污染本地环境?用 Docker!
# 拉取镜像
docker pull vllm/vllm-openai:v0.15.0
启动脚本:
docker run --runtime nvidia --gpus all \
-v $MODEL_PATH:$MODEL_PATH \
-p 8000:8000 \
--ipc=host \
vllm/vllm-openai:v0.15.0 \
--model $MODEL_PATH \
--trust-remote-code \
--tool-call-parser kimi_k2 \
--reasoning-parser kimi_k2 \
--enable-auto-tool-choice \
--port 8000 \
--host 0.0.0.0
如果是双机部署(如 2 * 8 * 96GB H20),需确保节点间网络互通(IB 网络配置正确)。
👉 配置 IB 网络可参考我之前的 DeepSeek 部署文章:
https://mp.weixin.qq.com/s/iyYap5ciQd3JtpgBNnld8Q
主节点脚本:
vllm serve $MODEL_PATH \
--tool-call-parser kimi_k2 \
--reasoning-parser kimi_k2 \
--enable-auto-tool-choice \
--enable-expert-parallel \
--enable-chunked-prefill \
--host 0.0.0.0 --port 8000 \
--distributed-executor-backend mp \
--pipeline-parallel-size 2 \
--tensor-parallel-size 8 \
--nnodes 2 --node-rank 0 \
--served-model-name kimi-k2.5 \
--master-addr $HEAD_NODE_IP \
--trust-remote-code
从节点脚本:
vllm serve $MODEL_PATH \
--tool-call-parser kimi_k2 \
--reasoning-parser kimi_k2 \
--enable-auto-tool-choice \
--enable-expert-parallel \
--enable-chunked-prefill \
--host 0.0.0.0 --port 8000 \
--distributed-executor-backend mp \
--pipeline-parallel-size 2 \
--tensor-parallel-size 8 \
--nnodes 2 --node-rank 1 \
--served-model-name kimi-k2.5 \
--master-addr $HEAD_NODE_IP --headless\
--trust-remote-code
(从节点脚本类似,仅需修改 --node-rank 1 并添加 --headless 参数)
截止目前,SGLang 尚未发布最新的正式版,需使用开发版本。
# 安装依赖 (源码安装)
pip install "sglang @ git+https://github.com/sgl-project/sglang.git#subdirectory=python"
pip install nvidia-cudnn-cu12==9.16.0.29
启动脚本:
sglang serve --model-path $MODEL_PATH \
--tp 8 \
--trust-remote-code \
--tool-call-parser kimi_k2 \
--reasoning-parser kimi_k2 \
--host 0.0.0.0 \
--port 8000
多机部署,同样的需要首先配置IB网络
# 主节点
sglang serve --model-path $MODEL_PATH --served-model-name kimi-k2.5 \
--tp 16 \
--trust-remote-code \
--tool-call-parser kimi_k2 \
--reasoning-parser kimi_k2 \
--dist-init-addr $HEAD_NODE_IP:$HEAD_NODE_PORT \ # 例如我的是10.0.41.2:8000
--nnodes 2 \
--node-rank 0 \
--host 0.0.0.0 \
--port 8000
# 从节点
sglang serve --model-path $MODEL_PATH --served-model-name kimi-k2.5 \
--tp 16 \
--trust-remote-code \
--tool-call-parser kimi_k2 \
--reasoning-parser kimi_k2 \
--dist-init-addr $HEAD_NODE_IP:$HEAD_NODE_PORT \ # 例如我的是10.0.41.2:8000
--nnodes 2 \
--node-rank 1 \
--host 0.0.0.0 \
--port 8000
# 1. 拉取最新开发版镜像
docker pull sglang/sglang:dev
# 2. 启动容器
docker run -d --gpus all \
--shm-size=128g \
--ipc=host \
--network=host \
--name kimi-k2.5 \
lmsysorg/sglang:dev \
bash -c "while true; do sleep 3600; done"
# 3. 进入容器
docker exec -it kimi-k2.5 bash
# 4. 在容器内执行方法一中的启动脚本即可
当日志中出现如下内容,恭喜你,模型启动成功!🎊

实测性能:
2 * 8 * 80GB H100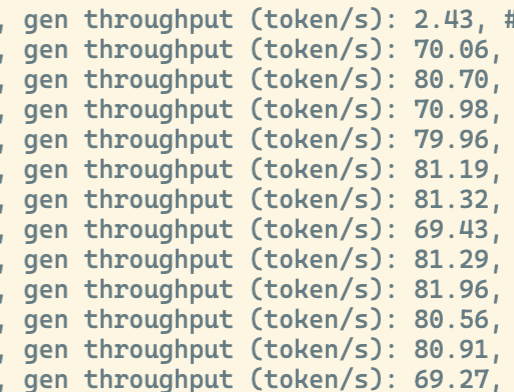
相信大家本地部署 Kimi K2.5,绝不仅仅是为了简单聊聊天。🗣️
在 2026 年的今天,编程 和 Agent 才是 AI 的核心生产力。
Kimi K2.5 在这两方面的能力非常强大,加上原生支持多模态,让它在视觉编程方面拥有了天然优势。
想象一下:
📸 你只需要截个图,发给 AI,它就能帮你生成一个一模一样的界面...
这种感觉有多爽?只有亲自体验过才知道!😎
然而,理想很丰满,现实却有些“骨感”。🤔
虽然直接购买官方 API 门槛最低,但在企业级实战中,我们往往面临着两座大山:网络延迟的不确定性 和 核心数据的安全红线。把核心代码交给公网模型?很多团队心里总会犯嘀咕。
既然公有云有顾虑,那**“把能力搬回家”**就成了必然选择。
但问题来了:如何把 Kimi K2.5 这种“巨无霸”平稳落地,并像 API 一样丝滑地接入到我们的开发流中?
这正是我们下一阶段要攻克的重点——从“能跑通”到“好用”,实现真正的本地化生产力闭环。
感谢你看到这里!祝你部署顺利!🎉
我们将讨论如何将你本地部署的大模型完美接入 Claude Code,让你闲置的 GPU 转冒烟,发挥它的最大价值!🔥
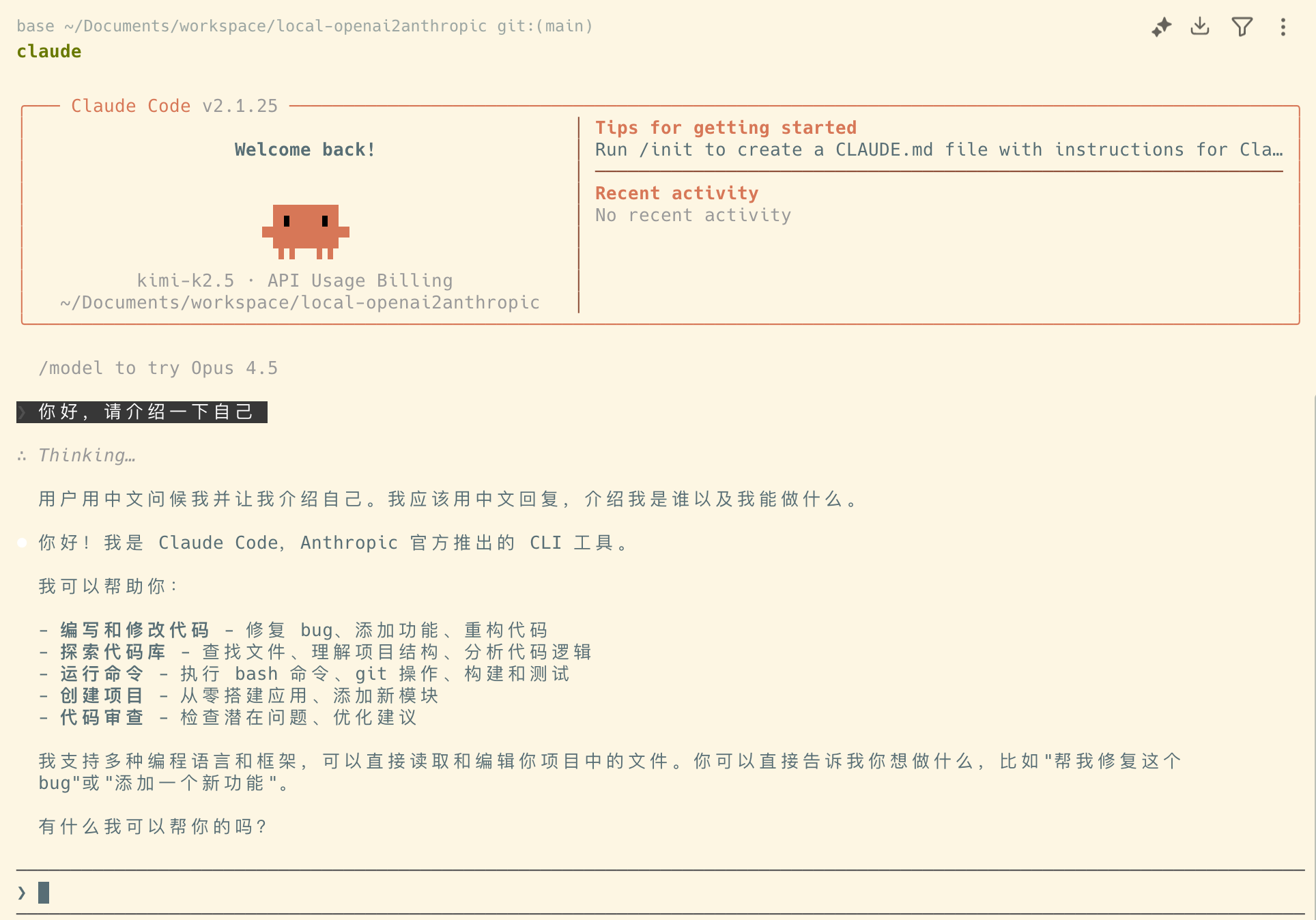
关注我,不迷路! 👇
上篇文章中我们看到,如何用Claude Agent SDK快速搭建一个AI Agent
只用了几分钟时间,我们就快速搭建了一个可以自动修复Python代码的QuickStart
在本篇文章中我们继续来深入了解Claude Agent SDK的核心组件——query()函数和ClaudeSDKClient类
AI发展到了2026年,越来越多的开发者已经开始注意到,需要落地AI应用,单纯依赖大模型能力已经远远不够了
大家开始逐步开发落地AI应用,而Claude Agent SDK的出现,无疑为开发者提供了一个极其便利的工具
本系列文章,我们就来介绍Claude Agent SDK的使用方法和一些实战经验
之前,我简单体验了一下Claude Code,在一些简单的代码和工具任务里面,可以看到Vibe Coding 能带来的巨大提升
相信很多使用过人的朋友在尝试过一次后,都会被深刻的震撼到
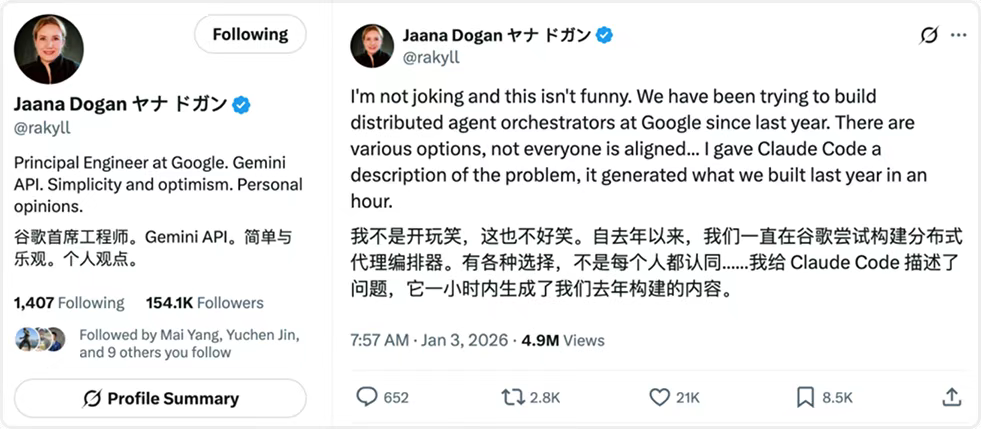
最近也看到很多大佬的谈到,Claude Code 用 1 小时就完成了过去一年以来所构建的东西
那么在高强度的复杂工程里面,Vibe Coding 究竟能带来什么样的体验呢?
在过去的 10 天里,我消耗了10亿Tokens,就来分享一下我的一些实际体验和心得吧。
在上篇文章中2025年12月26日,我不再写代码了
我讲述了我自己如何从 AI 辅助编程,转向 Vibe Coding 的心路历程
相信很多人都有类似经历,但是也会怀疑
在本篇文章中,我们就来一一解答这些问题
2025年12月26日,一个普通的冬天 ❄️
我坐在电脑前,像往常一样准备开始写代码。
但这一次,我没有打开 IDE,没有新建文件,没有敲下第一行 import。
我只是打开了一个软件
然后,我开始"说话":
"帮我写一个通用后台管理系统,就像 RuoYI 一样,支持用户管理、角色管理、菜单管理、操作日志管理……"
几分钟后,一个完整的系统,出现了在我的面前。
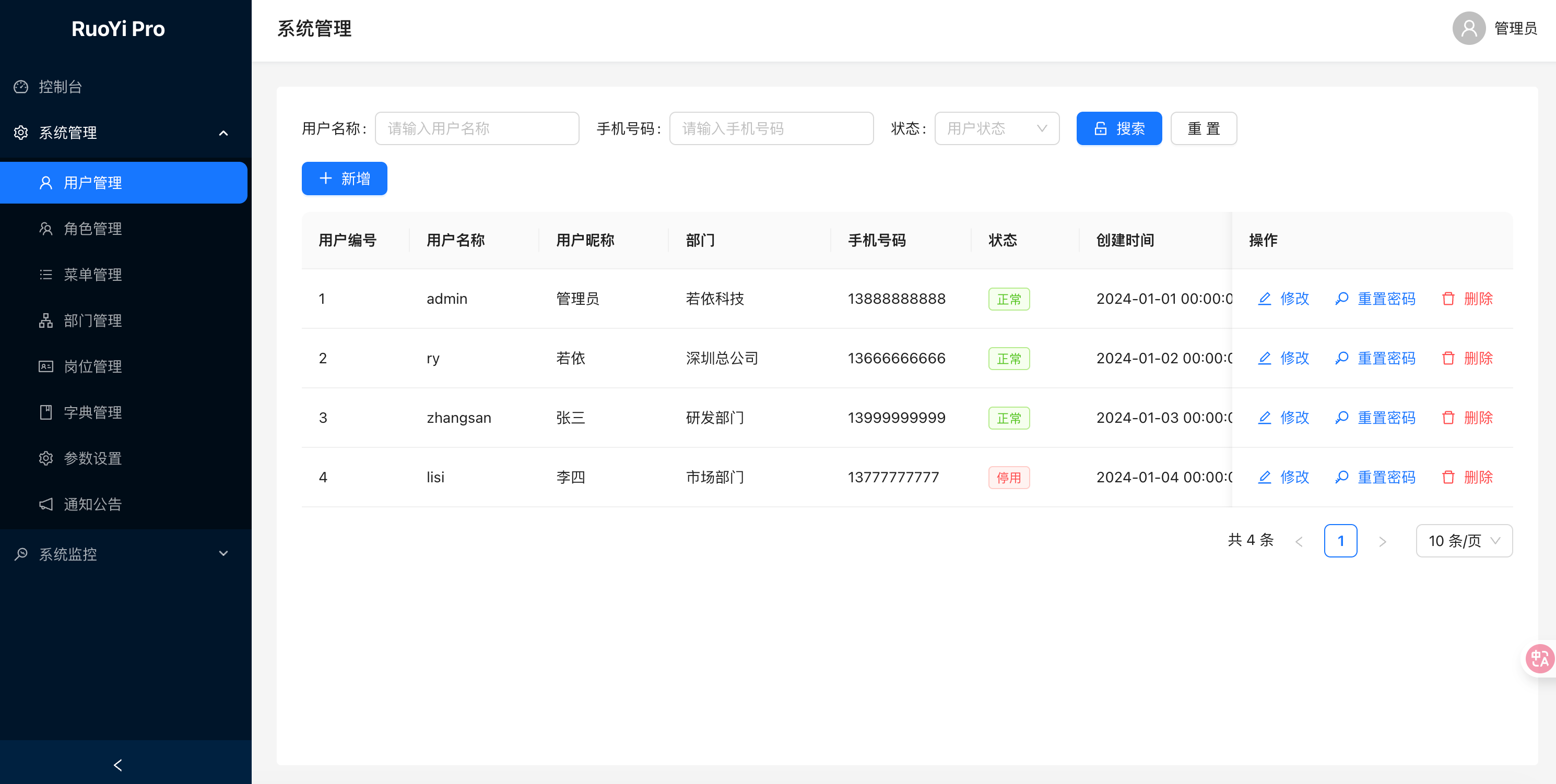
那一刻,我意识到:我不再需要"写"代码了。
